引言:
2025 SJTU CTF PWN方向题解,包含GuessMaster,ret2vmcode,TheLampSecret,ezshellcode四道赛题
1 GuessMaster
看程序是一个随机数预测,一百次预测成功之后就会给两次溢出机会。
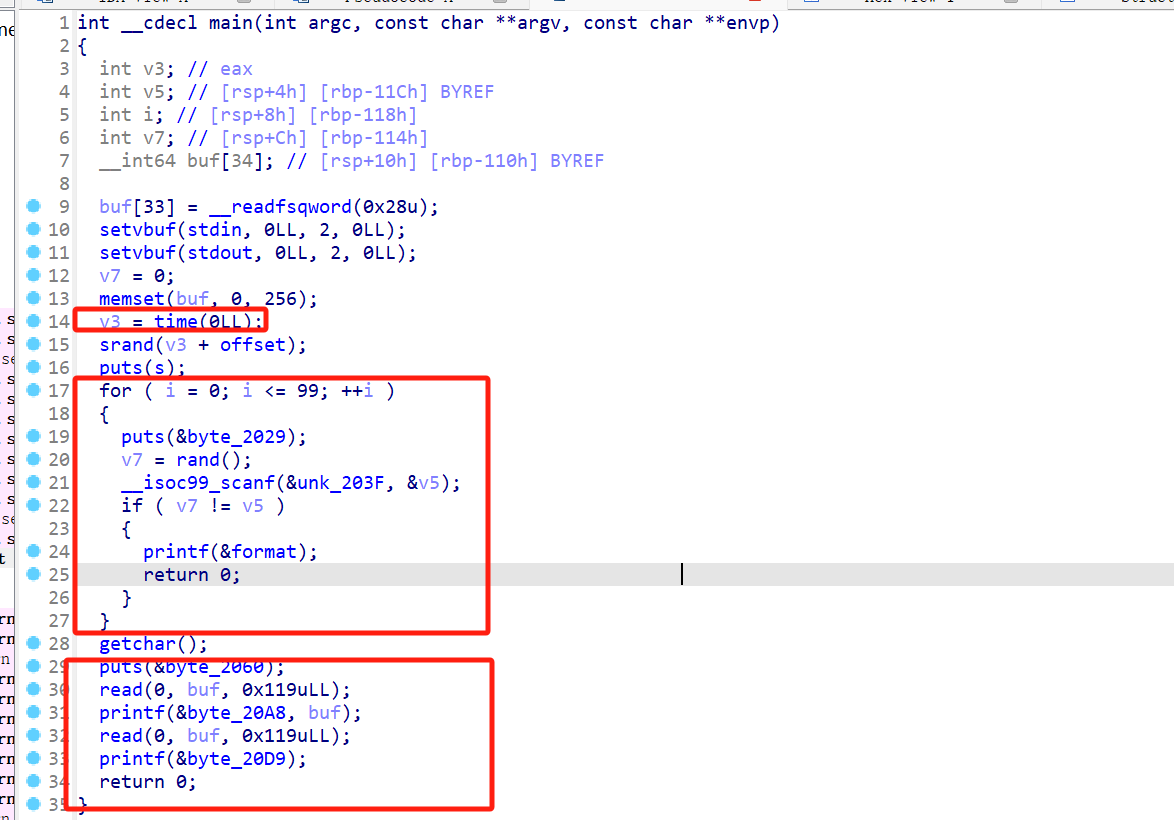
程序开了canary,time(0LL)就是拿当前时间戳,只要网速够快就可以保证本地和远端时间戳同步,加上offset就可以得到随机数种子。
这个offset虽然在IDA里看是0xa,但是在start里面好像会对这个变量做一堆莫名其妙的变化。GDB动调一下发现最后的offset是0x6e

程序还给了个后门函数,那就直接随机数预测+canary泄露+ret2text一把梭:
1 | import ctypes |
2 ret2vmcode
一个opcode的题目,给了很多操作原语,先阅读理解一下。
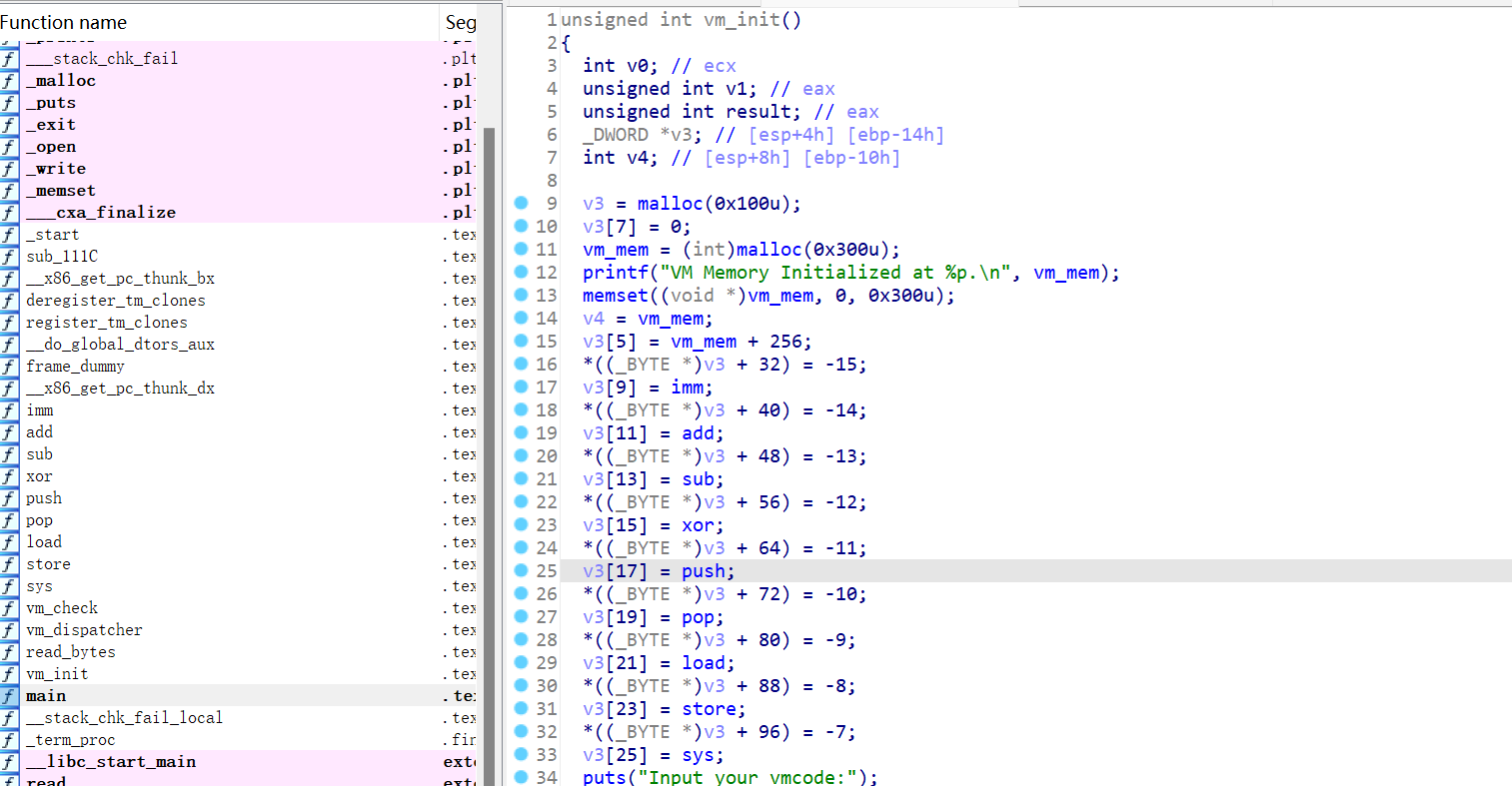
一个操作原语是9个字节,第一个字节表明这是什么操作,然后剩下八个字节前四个代表一个操作寄存器,后四个代表一个操作寄存器,而且程序的寄存器只有4个可用:
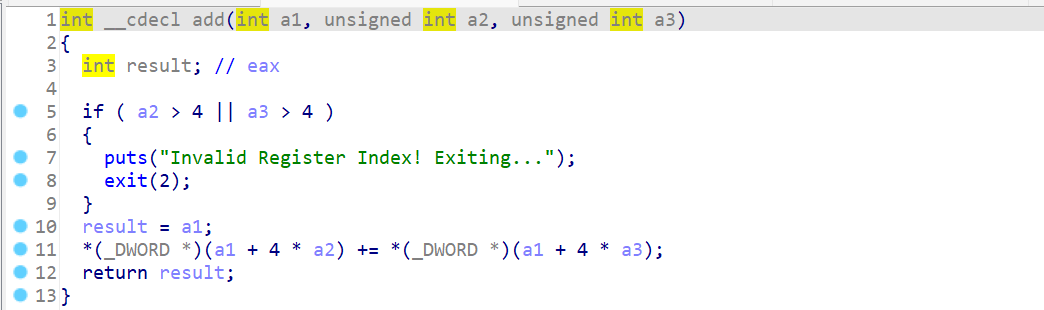
把所有代码给Claude 3.7 sonnet,让他给我阅读理解一下。
这个程序一共分配0x300字节大小的虚拟内存空间,并且表明前0X100字节是指令区,后0x200字节是数据区。
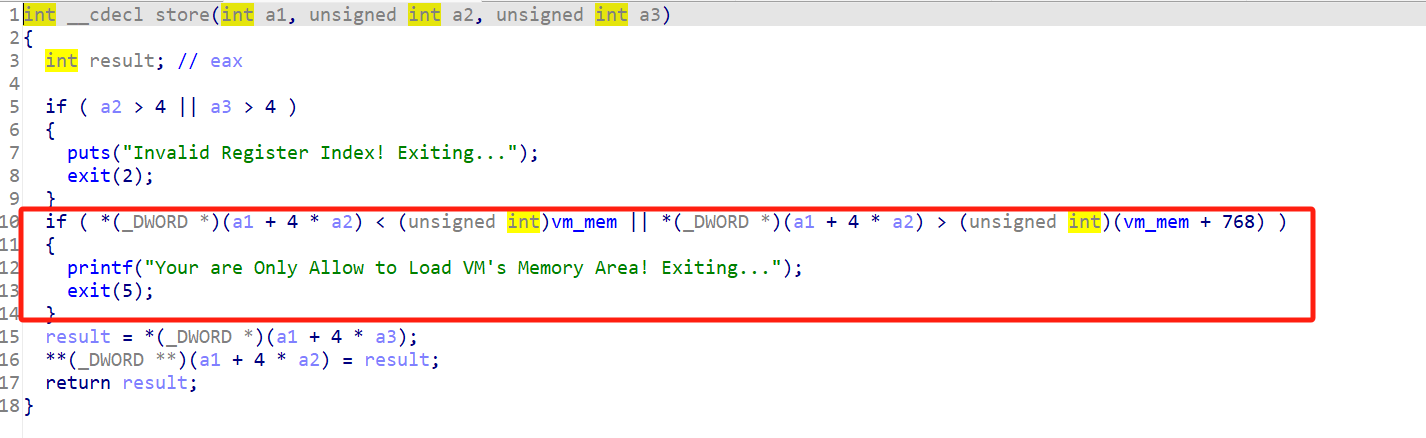
可以通过操作原语修改vm内存区的任意地址内存,这里并没有任何限制:
发现程序还提供了一个syscall的操作原语:
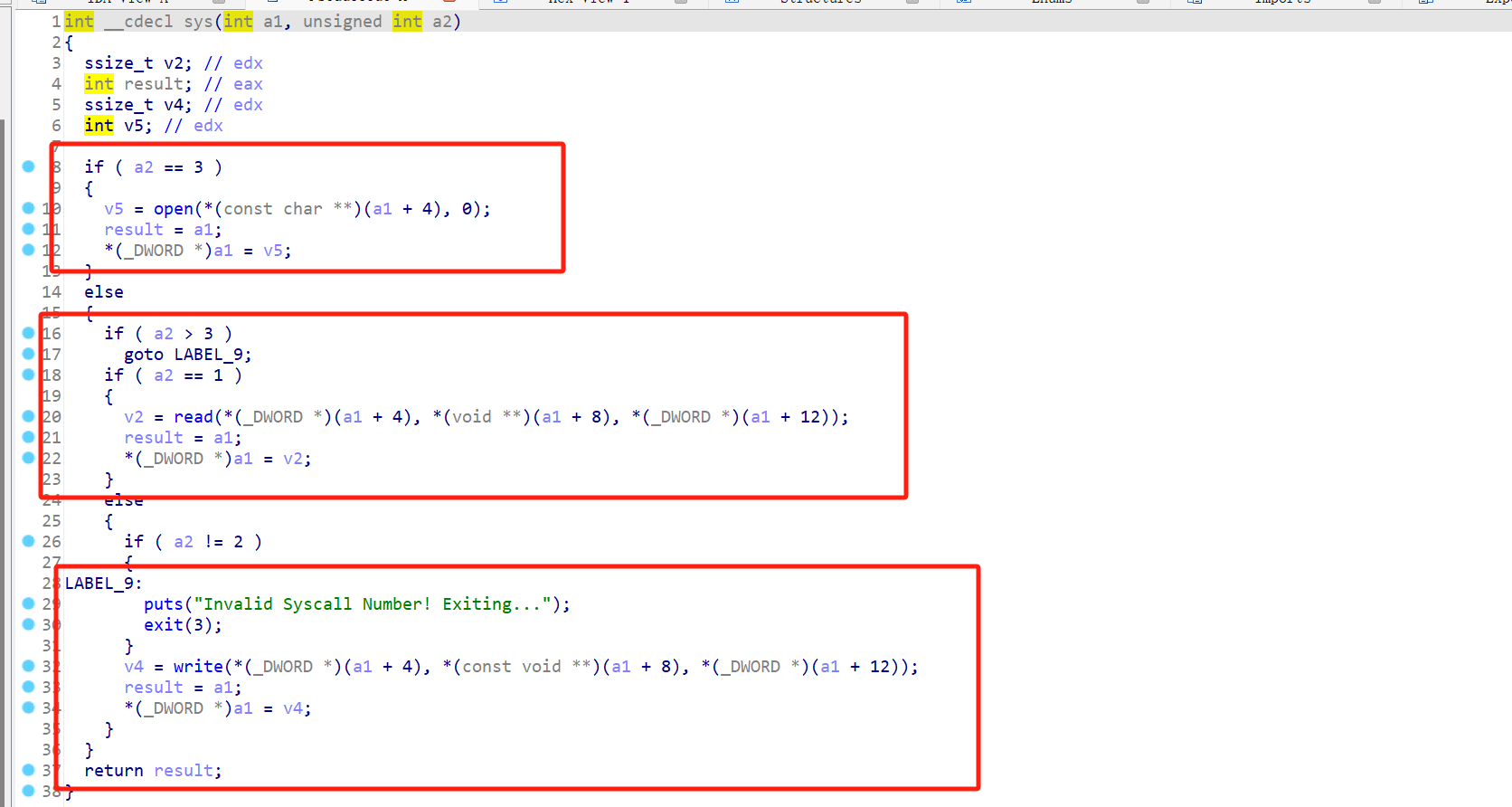
很给的ORW,所以本题的目的就是通过ORW来获取flag的内容。
但在main函数中对输入的字符有限制,不能出现0xf9, 对应sys操作的标识符。
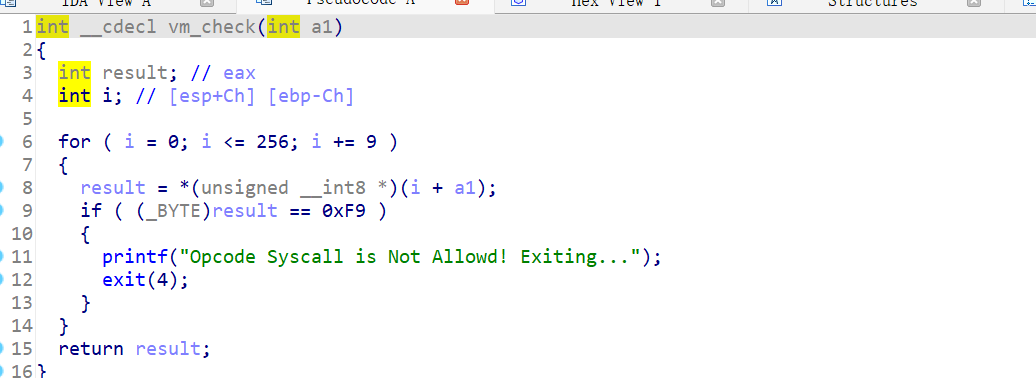
没关系,从store和load中可以看到程序并没有对指令操作的地址有任何限制,也就是我们可以通过前面的指令去修改后面指令的标识符,来绕过这个检测。
思路可行,exp如下:
1 | from pwn import * |
需要注意本题只能输入0x100个字节,所有orw,在r之后,后两个寄存器不用变,直接改第一个寄存器即可完成w,节省空间。
本地运行题目,获取flag:

3 TheLampSecret
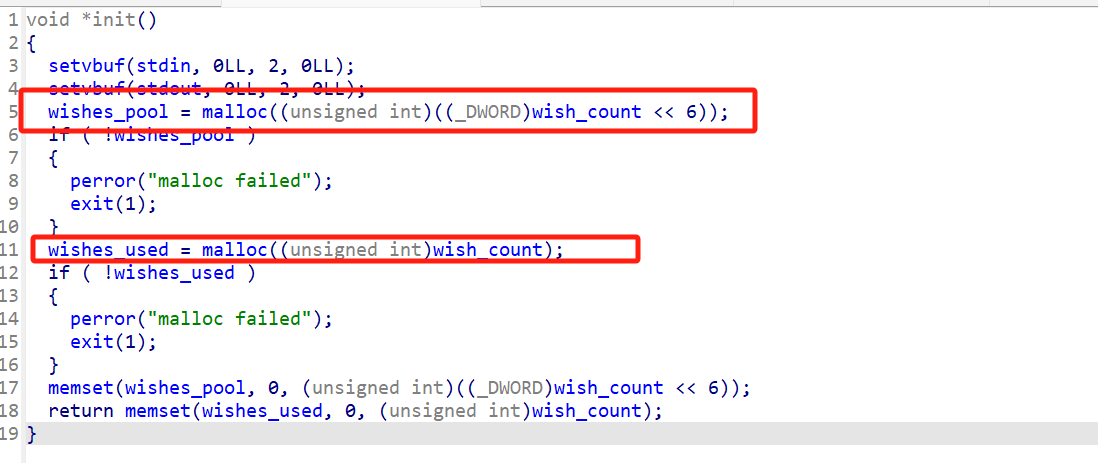
一个堆题,但又不那么堆。程序大意是一个许愿的功能,在init里会分配两个堆块,一个是许愿池,一个是标记许愿池里每0x40(一个愿望)的使用情况。
wish_count << 6表明了每个愿望的大小就是0x40字节。

程序提供了几个功能,许愿,查看愿望,编辑愿望,删除愿望,重置愿望还有一个thank tomorin
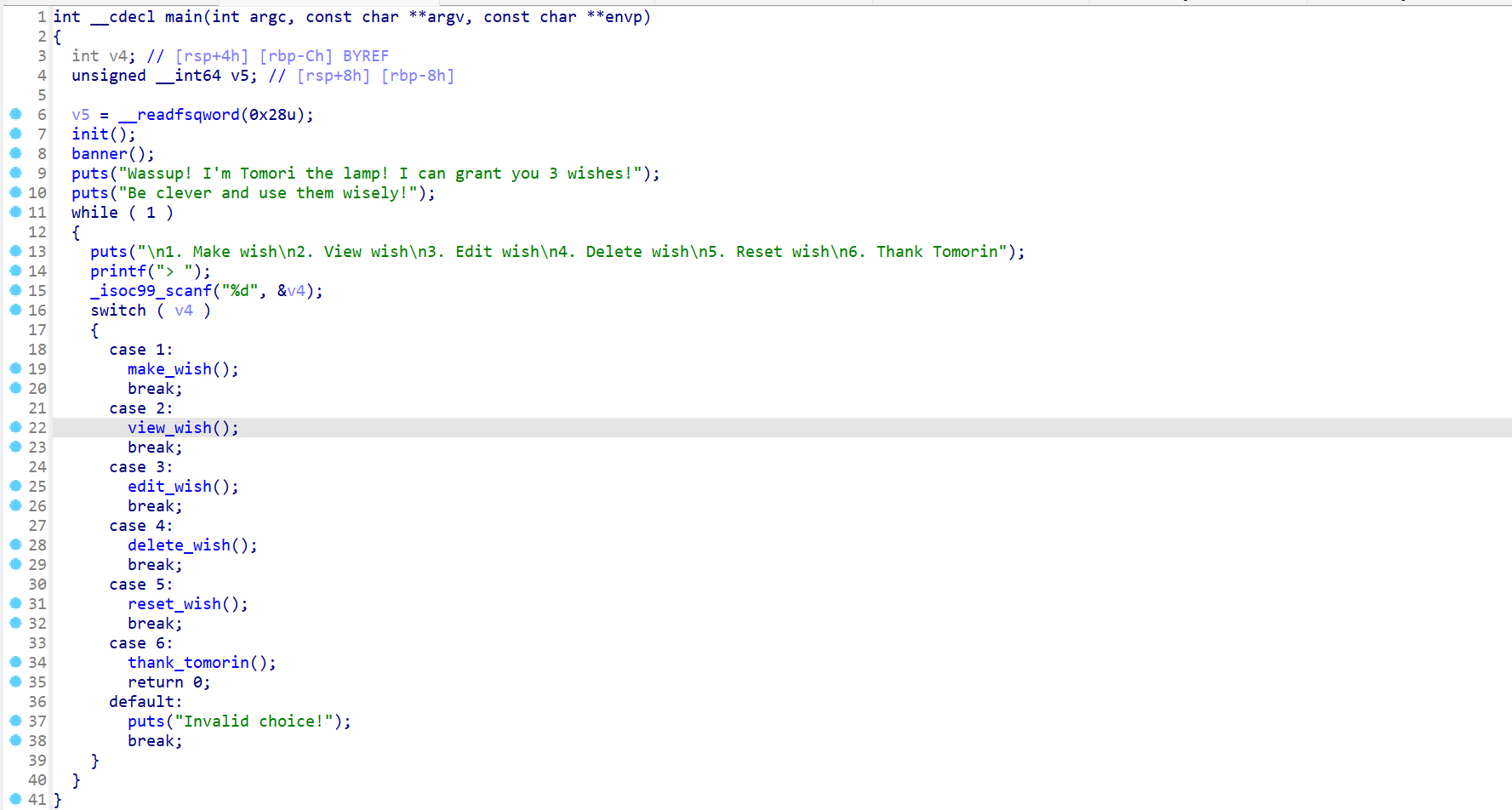
make view edit delete都没什么洞,主要还是reset和thank
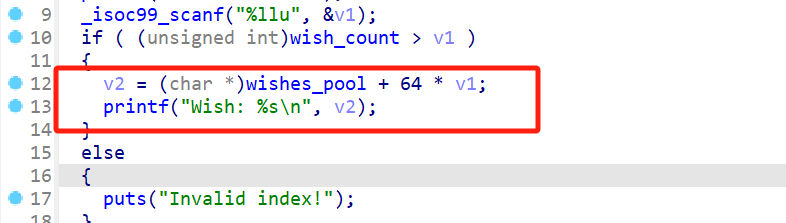
先看thank, 是白给的一个栈溢出,但程序里没有提供后门函数,而且开了PIE,想要溢出还要泄露canary。
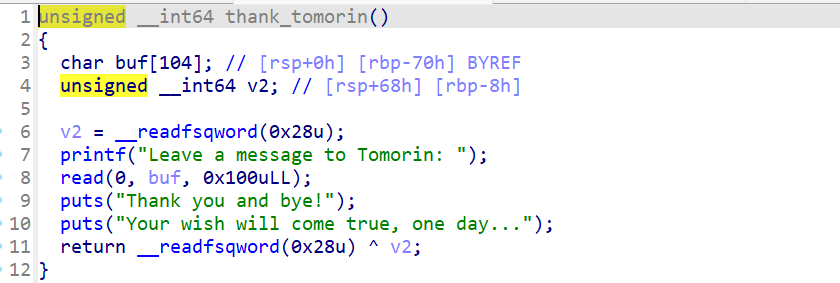
在reset里可以重置愿望池子,这里有一个很明显的负数溢出的漏洞。当我们输入wish_count是0时,会绕过wish_count > 3d的检测,下面会把wish_count - 1,就变成了一个很大的无符号整形数。接下来由于这个count特别大,最终分配的新的愿望池子的size就是0x114514
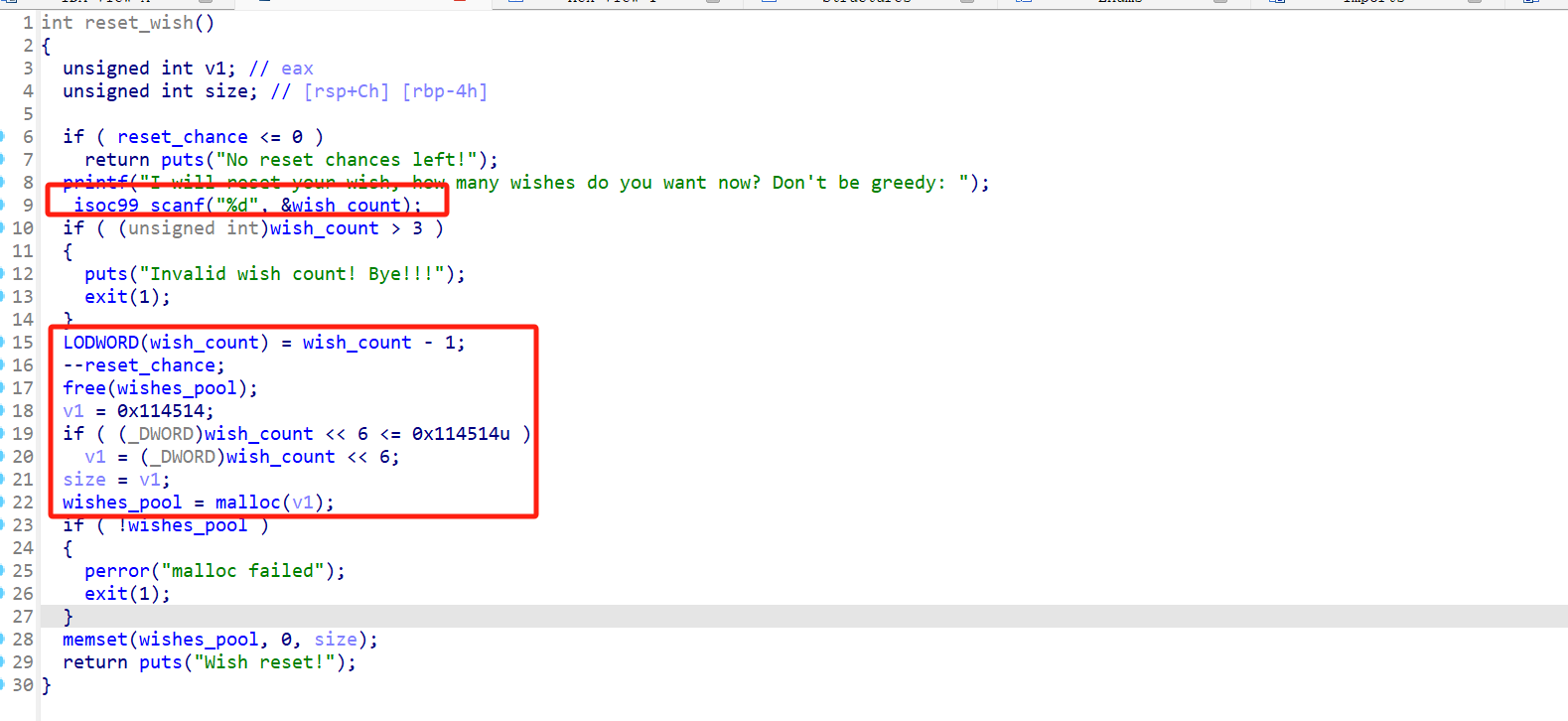
虽然但是,老子一开始是按照我0xffffffff的count分配的,你私自把size改小没通知count,导致这里间接出发了一个很严重的越界访问读写的漏洞。
从之前几个函数的操作中可以得知,他们对于愿望池的内存访问都是根据wish_count来的,所以我现在可以越界访问堆块外的数据。
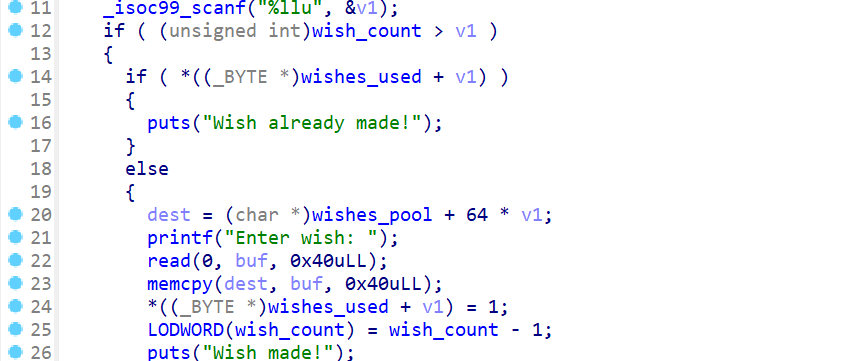
由于分配的堆块是0x114514大小,是一个很大的大堆块,会分配在一个高地址区间,这个地址区间有两个更高地址的邻居:
TLS-> 泄露canary__rtld_global-> 打exit_hook

一开始想泄露canary,但是看了下view_wish, %s输出我泄露个蛋。
看Dockerfile, ubuntu:16.04 果断打exit_hook
1 | FROM ubuntu:16.04 |
打
exit_hook的触发条件是程序通过exit显式退出,或者程序通过main函数正常返回,在libc 2.23 - 2.26有效需要能写到
ld加载段,可以有两种修改_rtld_global的方式,任选其一:
- 改
rtld_lock_default_lock_recursive或rtld_lock_default_unlock_recursive为system,_dl_load_lock为/bin/sh\x00
2
3
4
5
6
► 0x7fb213ac5dd1 <_dl_fini+113> call qword ptr [rip + 0x1d191] <execvpe+638>
rdi: 0x7fb213ae2968 (_rtld_global+2312) ◂— 0x0
rsi: 0x0
rdx: 0x7fb213ac5d60 (_dl_fini) ◂— endbr64
rcx: 0x1
- 改
rtld_lock_default_lock_recursive或rtld_lock_default_unlock_recursive为 one_gadget
2
3
4
5
rdi: 0x7f83b9c53968 (_rtld_global+2312) ◂— 0x0
rsi: 0x0
rdx: 0x7f83b9c36d60 (_dl_fini) ◂— endbr64
rcx: 0x1三者在
_rtld_global中的偏移如下:
2
3
4
5
_rtld_global = ld_base + ld.sym['_rtld_global']
_dl_rtld_lock_recursive = _rtld_global + 0xf08
_dl_rtld_unlock_recursive = _rtld_global + 0xf10
_dl_load_lock = _rtld_global + 0x908
我们还需要泄露一个libc基地址,make里面是使用memcpy把buf里面的数据拷贝到愿望池中的,但在这之前并没有对buf进行清空操作,在view输出的时候就会把栈上的脏数据也一起拉出来。只要获得一个libc段的地址, 再减去偏移,就可以获得基地址。

本题的exp如下:
1 | from pwn import * |
本地运行获取shell:

4 ezShellcode
手搓不可见字符shellcode 比手搓可见字符简单多了。
可以输入0x100个字节,strlen要求不能有\x00字符,不然会被截断,下面还有一个check,函数里面的意思就是保证shellcode里不能有[A-Za-z0-9]
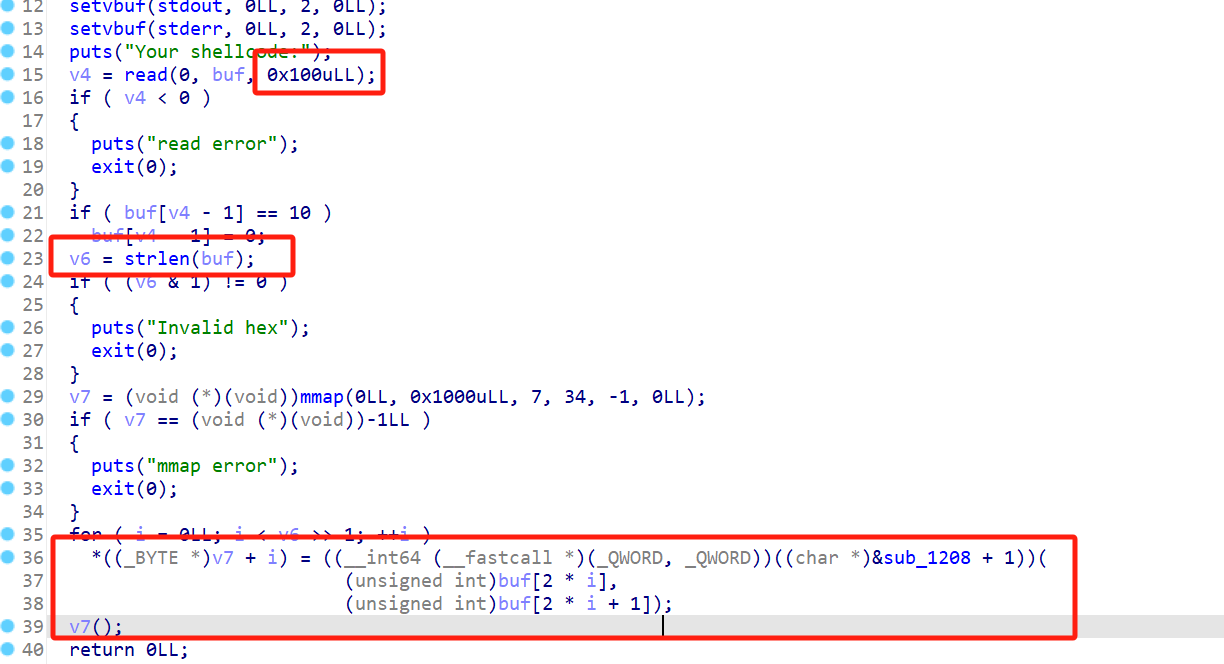
这题跟一般题目还有一个不一样的点就是,他会把输入的东西进行一个转换,转换之后的才是要执行的shellcode。
直接把转换逻辑丢给AI让他帮我逆了,看起来就是取相邻的两个字节,进行一个类似BCD码的转化(不懂啊不懂啊)。
明确以下几条规则:
- x86/64下大多数对32位寄存器的操作不产生可见字符
- 在跳转指令中
jg, jge等无符号数比较不产生可见字符 jmp qword ptr指令不产生可见字符(除非偏移的数值中产生可见字符)mov dword ptr []指令不产生可见字符(除非偏移的数值中产生可见字符)- 针对32位寄存器的立即数操作,立即数会被对齐到32位,如果位数不够会产生
\x00 syscall是\0xf \0x5,没有可见字符

本题思路如下:
- 第一次输入
shellcode由于会被校验,所以直接拿shell不现实,这里一般思路是获取栈上在call rax时被压进去的返回地址,跳转到read函数再来一次华丽的输入。 - 由于本题机制的原因,假如我们第一次返回到了
read函数重新输入,这时候输入的地址是我们第一次mmap的地址,但read之后会在进行一次mmap, 这时候v8会被刷新为一个新的地址,那么存入new v8的数据,就是栈上的buf。注意这个buf, 等我们第二次mmap的时候,buf里存储的仍然是我们第一次输入的shellcode, 最终会call new v8, 再次运行一遍我们第一次输入的shellcode。 - 所以我们需要让一份
shellcode, 在两次运行时,执行不同的功能:- 第一次运行,获取栈上保存的返回地址,跳转到
read函数,进行old v8内存的覆写,并将old v8指针保存在栈上,设置计数器 - 第二次运行,检查计数器,如果已经被执行过,获取第一次运行时保存在栈上的
old v8, 跳转过去,getshell
- 第一次运行,获取栈上保存的返回地址,跳转到
栈真是个好东西,虽然程序在运行时会在函数里call 来call去,但是我
rbp岿然不动,这里面还涉及到很多动调的细节,比较考验耐心就是了。
本题exp如下:
1 | from pwn import * |
运行exp,获取shell:
