引言:
Ptmalloc 内存管理数据结构,备忘笔记。
主分配区(Main_arena)与非主分配区(Non_main_arena)
fastbin机制
glibc 2.23 ~ glibc 2.25
fastbin堆块大小范围:0x20~0x7f
在堆内存管理中,Fastbins 是一种用于管理小块内存分配的高速缓存机制。Fastbins 存储相对较小的内存块,以便在分配和释放内存时提供快速的性能。
Fastbins 的范围通常取决于具体的堆实现和平台架构。以下是一些常见的范围示例:
glibc(Linux 系统下的 GNU C 库):Fastbins 的范围通常是从 0x20 字节到 0x80 字节(不包括 0x80 字节)。也就是说,当请求的内存块大小在 0x20 到 0x7F 字节之间时,glibc 会使用 Fastbins 进行分配和释放。
Windows Heap(Windows 系统下的堆管理):Fastbins 的范围通常是从 0x20 字节到 0x80 字节(不包括 0x80 字节),类似于 glibc。
malloc
在从free fastbin从取出空闲块malloc的时候,会有如下比较

比如说我们实际需要的块大小(包括header是0x40),那么只要当前将要被取出的free fastbin size在0x40~0x4f之间,就可以通过比较,不然就报错
一般在double free的时候,我们可以把指针改到libc里面,这样就可以任意地址写,但在把这个地址malloc出来的时候会做一遍大小check,所以一般fastbin attack需要分配到malloc_hook-0x23,这里对应的size是0x7f,只要我们malloc(0x68)就可以过了check
free
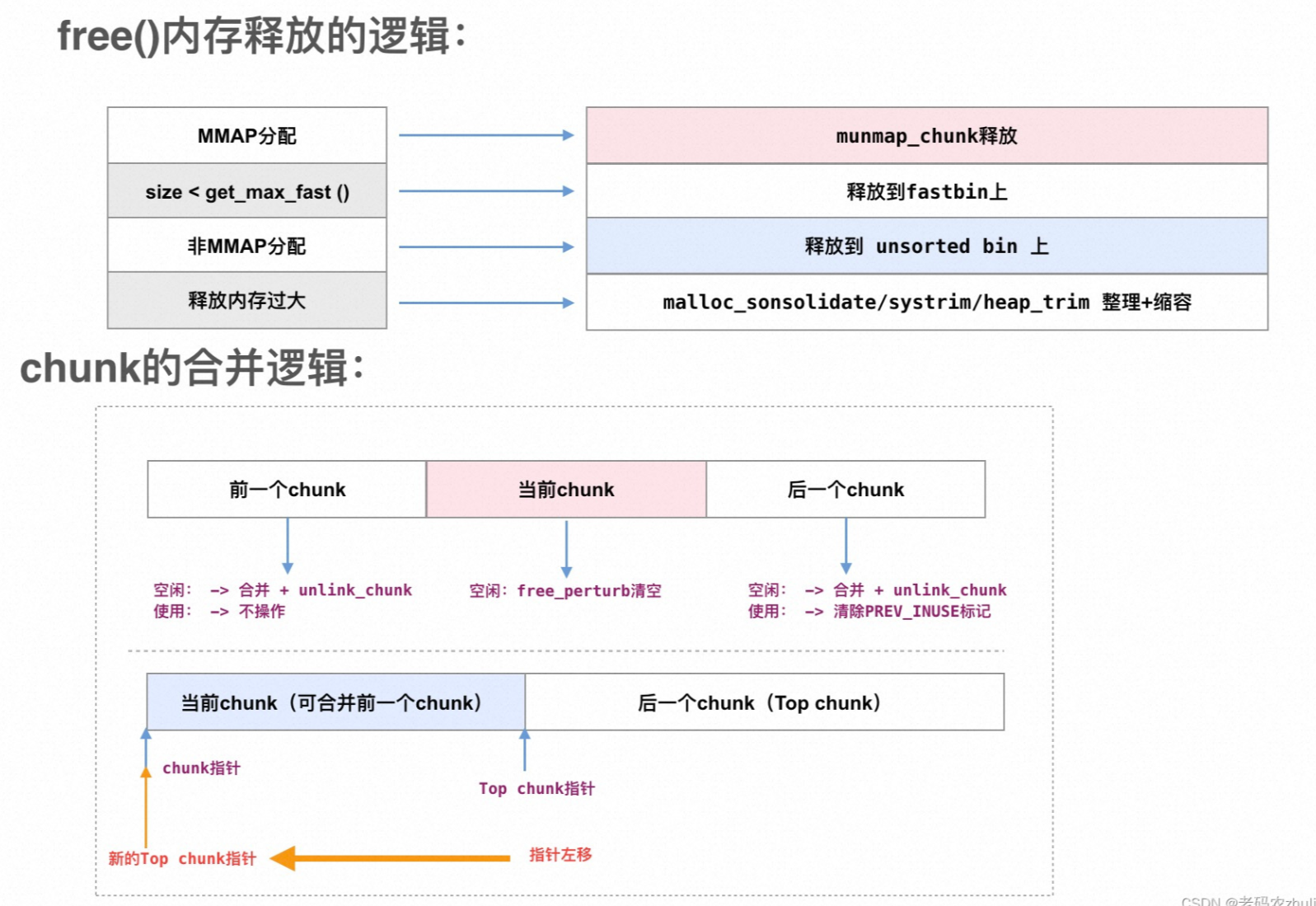
free函数的基本步骤有6步:
步骤1:如果是MMAP分配的,则调用munmap_chunk进行chunk的释放操作
步骤2:如果释放的内存小于get_max_fast(),则释放的chunk放入fastbin
步骤3:如果不是MMAP分配,则释放的时候释放到unsorted bin
步骤四:如果释放的chunk的nextchunk 就是Top chunk,则直接扩容Top chunk
步骤五:如果释放的内存比较大,则需要对chunk进行一些缩容处理
步骤6:MMAP方式分配的,则直接执行munmap_chunk
__malloc_hook fake chunk伪造
- 可找寻的内存:0x7f
- 第一个
0x7f距离malloc_hook的上偏移一般为19, fake_chunk头距离malloc_hook距离一般为0x23 - 前填充0x13个,然后填充
one_gadget
tcache bin 机制
1 | struct tcache_perthread_struct { |
在 glibc 2.26 中,tcache 机制是首次引入的,而内存分配的具体策略和实现方式与后续版本基本相似。关于 tcache bin 的下标计算,不同大小的内存块按 8 字节对齐。
为了确定 glibc 2.26 中 0x250 大小的内存块在 tcache 中的 counts[] 数组对应的下标,我们仍然需要按照类似的思路计算。不过,glibc 2.26 中使用了固定的映射规则,将特定大小的内存块映射到 tcache bin。
以下是详细步骤:
- 最小块大小是 0x20(32 字节):tcache bin 起始于 0x20。
- 每个 bin 的增量是 0x10(16 字节):tcache bin 增量是每 16 字节一个
bin。
在这种情况下,计算 0x250(592 字节)的内存块在 tcache bin 中的下标的公式如下:
1 | i = (0x250 - 0x20) / 0x10 |
边界标记法与空间复用
1 | /* |
malloc_chunk来说size是必须的,标志了这个chunk的大小,来决定是否满足malloc的要求,那么对于空闲的malloc_chunk来说fd,bk,fd_nextsize,bk_nextsize是必须的,bin中的空闲双链表;
对于非空闲的malloc_chunk来说,fd,bk,fd_nextsize,bk_nextsize是没有用的,所以这部分空间被作为了可用的空间。
那么prev_size就比较复杂了,它的状态取决于虚拟地址相邻前面的chunk的状态:
- 如果前面的chunk是使用状态,那么这个chunk的prev_size就没有意义了,也没有合并的必要了,所以就不需要知道前面chunk指针的位置了,所以这个变量的空间被前面的chunk征用了。
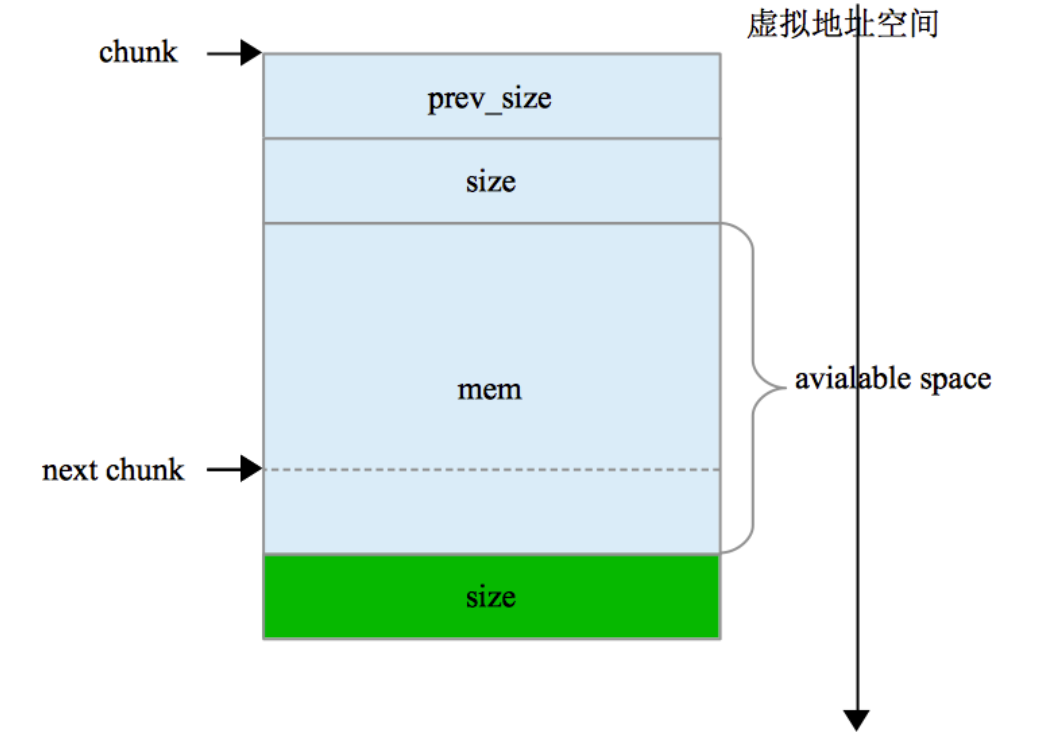
malloc请求的size,要加上结构体的数据大小才和malloc_chunk的size有可比性。
1 |
从上面的宏可以看出实际请求的大小是req再加上size_t然后对齐,这里prev_size和size不是应该2*size_t么,但是还要计算上next chunk赠送的prev_size的size_t。
从上面的分析可以看出malloc_chunk设计是巧妙的,prev_size字段可以通过它来找到地址相邻空闲的上一个chunk,使得合并空闲的chunk十分方便,同时如果当前chunk的前一个chunk是使用中的,prev_size的空间可以借给上一个chunk作为可用空间。
off-by-one
off-by-one指的是单字节缓冲区溢出(off-by-one 是可以基于各种缓冲区的,比如栈、bss 段等等) 写入字节时超过本身申请的一个字节
- 循环设置错误,多写了一个字节
- 字符串长度判断有误 strlen()计算字符串的长度不包括空结束字符 调用gets函数后 字符串结束符自动添加到输入字符串末尾 strcpy拷贝时候会把空结束字符也拷贝
- 利用思路
- 当溢出部分可控制任意字节时,且溢出部分为size段时,可修改大小,进而泄露其他chunk数据或者覆盖其他块的数据
- 利用思路
当溢出部分固定为NULL字节时,且溢出部分为size段时,且size大小为0x100的整数倍时,它的低字节会被清0,同时标志位都会被清0,这样前一个chunk块会被认为free块
- 可以利用unlink
- 可以利用同时构造pre_size和对应的NULL字节溢出,然后unlink时合并,此方法的关键在于 unlink 的时候没有检查按照 prev_size 找到的块的大小与prev_size 是否一致。
注意2.28版本以后有check检查prev_size 找到的块的大小与prev_size 是否一致,2.28 及之前版本并没有该 check
1 | /* consolidate backward */ |