引言:
2023年ZJUCTF-Pwn方向部分题题解,包含rev signin, ZJUdorm, if-else, verifier。因为时间分配的问题,大块时间给pwn和misc了,reverse部分做的题比较少。其中三道题都是算法逆向,一道控制流。做逆向感觉就是,一支笔一根烟一行代码逆一天(×)。很需要耐心,是真的努力的天才。有哪里写的不对的地方还请指出呜呜...
1 rev signin
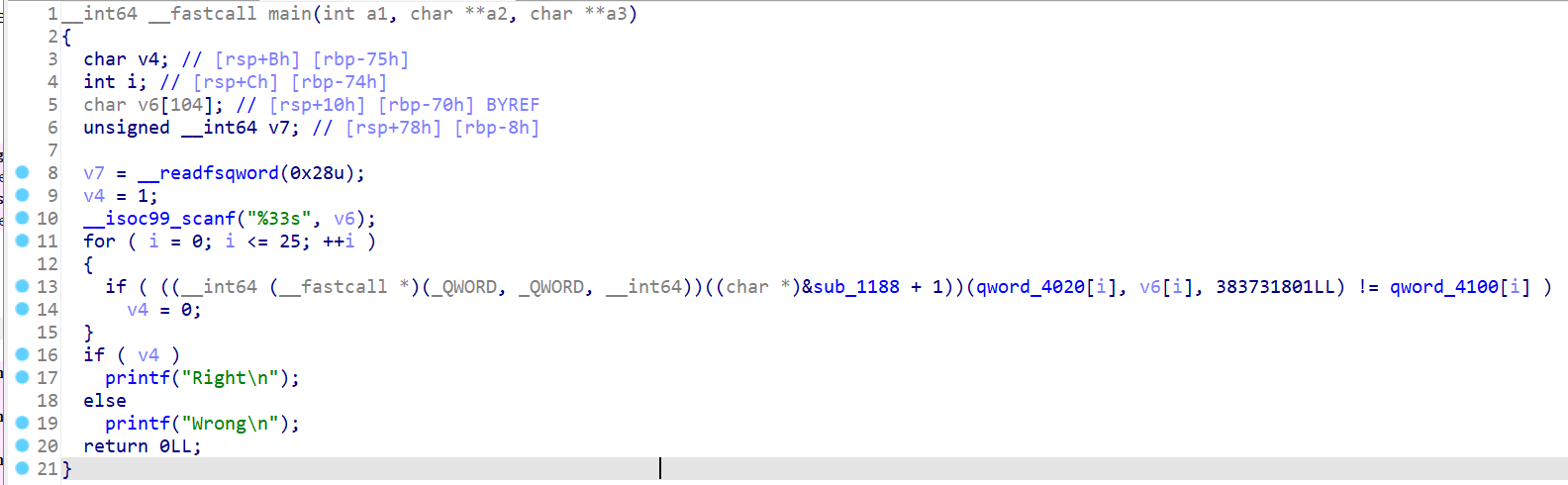
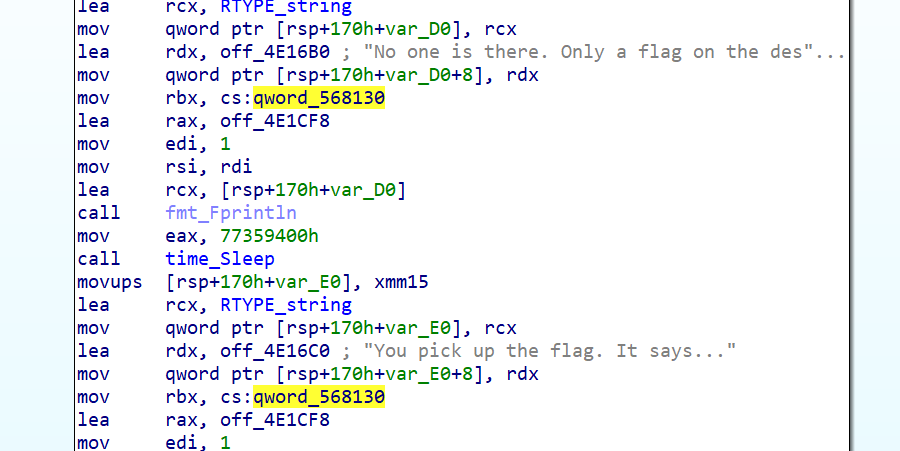
打开,是一段程序。中间有一个,及其抽象的调用。注意函数的调用形式,取了标号的地址加1,再进行传参。
OK,锁定标号,找到+1的位置,在这里创建一个函数标号,再次反汇编,就可以看到加密函数了。
好好好,不出所料贼抽象的东西。
程序大意就是我们输入一个字符,经过加密函数这一通加密之后可以等于一个在某个内存地址中的值。
内存地址中的值我们是可以得到的。
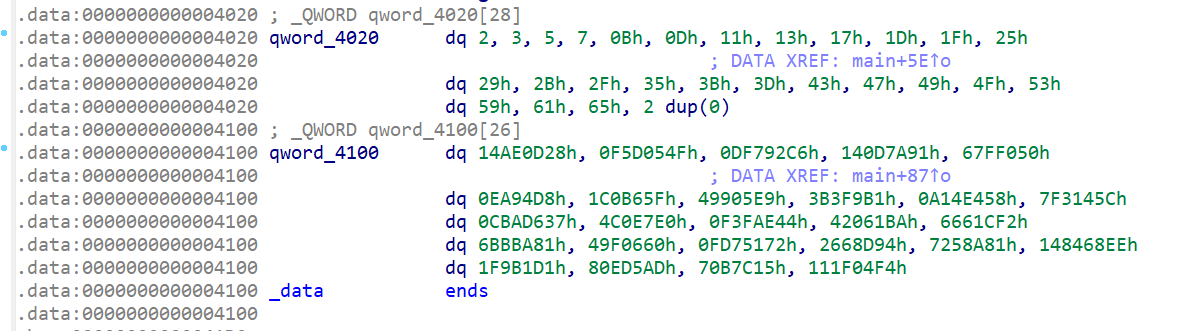
qword_4020是一个double类型的数组,用于辅助加密,也可以理解为是密钥。
qword_4100是一串密文。
可以看到这两个东西的长度是相同的。
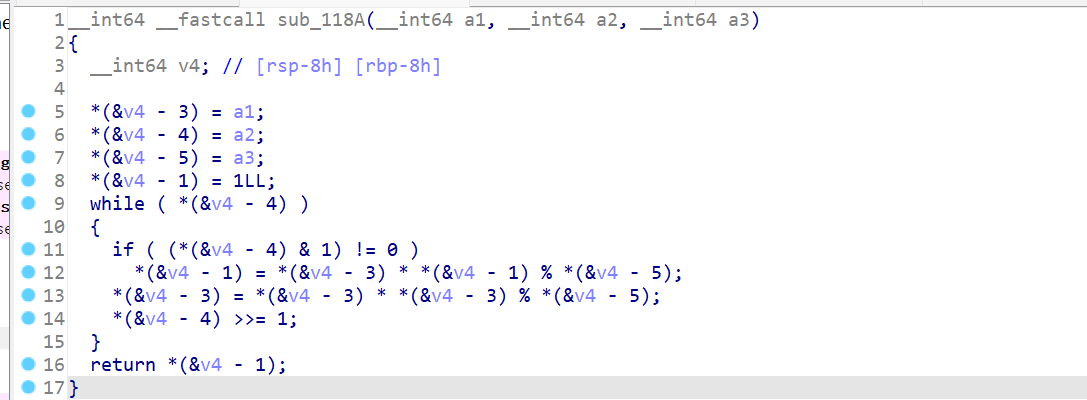
观察加密算法,md取余?取余怎么搞?
对于逆向算法而言,移位可以移回去,异或可以异回去,加减乘除都可以逆,唯独取余不好办。。。。
但还好,由于本题明文,密钥,密文都是线性映射的,而且明文的数量也很有限(可见字符),所以可以爆破出来:
解密算法如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 key = [2 ,0x3 ,0x5 ,0x7 ,0x0B ,0x0D ,0x11 ,0x13 ,0x17 ,0x1D ,0x1F ,0x25 ,0x29 ,0x2B ,0x2F ,0x35 ,0x3B ,0x3D ,0x43 ,0x47 ,0x49 ,0x4F ,0x53 , 0x59 ,0x61 ,0x65 ] text_cry = [0x14AE0D28 ,0x0F5D054F ,0x0DF792C6 ,0x140D7A91 ,0x67FF050 ,0x0EA94D8 ,0x1C0B65F ,0x49905E9 ,0x3B3F9B1 ,0x0A14E458 ,0x7F3145C ,0x0CBAD637 ,0x4C0E7E0 ,0x0F3FAE44 ,0x42061BA ,0x6661CF2 ,0x6BBBA81 ,0x49F0660 ,0x0FD75172 ,0x2668D94 ,0x7258A81 ,0x148468EE ,0x1F9B1D1 ,0x80ED5AD ,0x70B7C15 ,0x111F04F4 ] def encode (a1, a2 ): result = 1 while a2 != 0 : if (a2 & 1 ) != 0 : result = a1 * result % 0x16DF4859 a1 = a1 * a1 % 0x16DF4859 a2 = a2 // 2 return result flag = "" for i in range (len (key)): for j in range (0x20 , 0x7F ): if encode(key[i], j) == text_cry[i]: flag += chr (j) break print (flag)
2 ZJUdorm
怎么说呢,因为它是一道trivial难度的题,所以我觉得它没那么难。
载下来一个exe文件,试运行一下:
看来也是个加密算法,但是好像前面这段文字跟flag没半毛钱关系。
扔进IDA看一下:
这里是用IDA freeware打开的,不知道为什么IDA64打开就什么都没有。
但是IDA freeware的F5还是相当不稳定的,比如这里我就看不了C源码
看他的字符串提示,好像咱们只要输入了正确的数字就能弹flag。
那为什么不直接拿flag?
用GDB调试不就得了.....好吧调不了,再打开文件看看,原来开了反调试。
那就继续跟着上面的It says往下找呗
发现一个好多参数的内存地址传参函数,之后就调用print输出字符串了,盲猜这个b东西就是生成flag的算法。
没办法freeware太渣了,生成不了源代码,那就直接!看汇编!!
果然是trivial叭,分析来分析去,那么一大堆都没用。
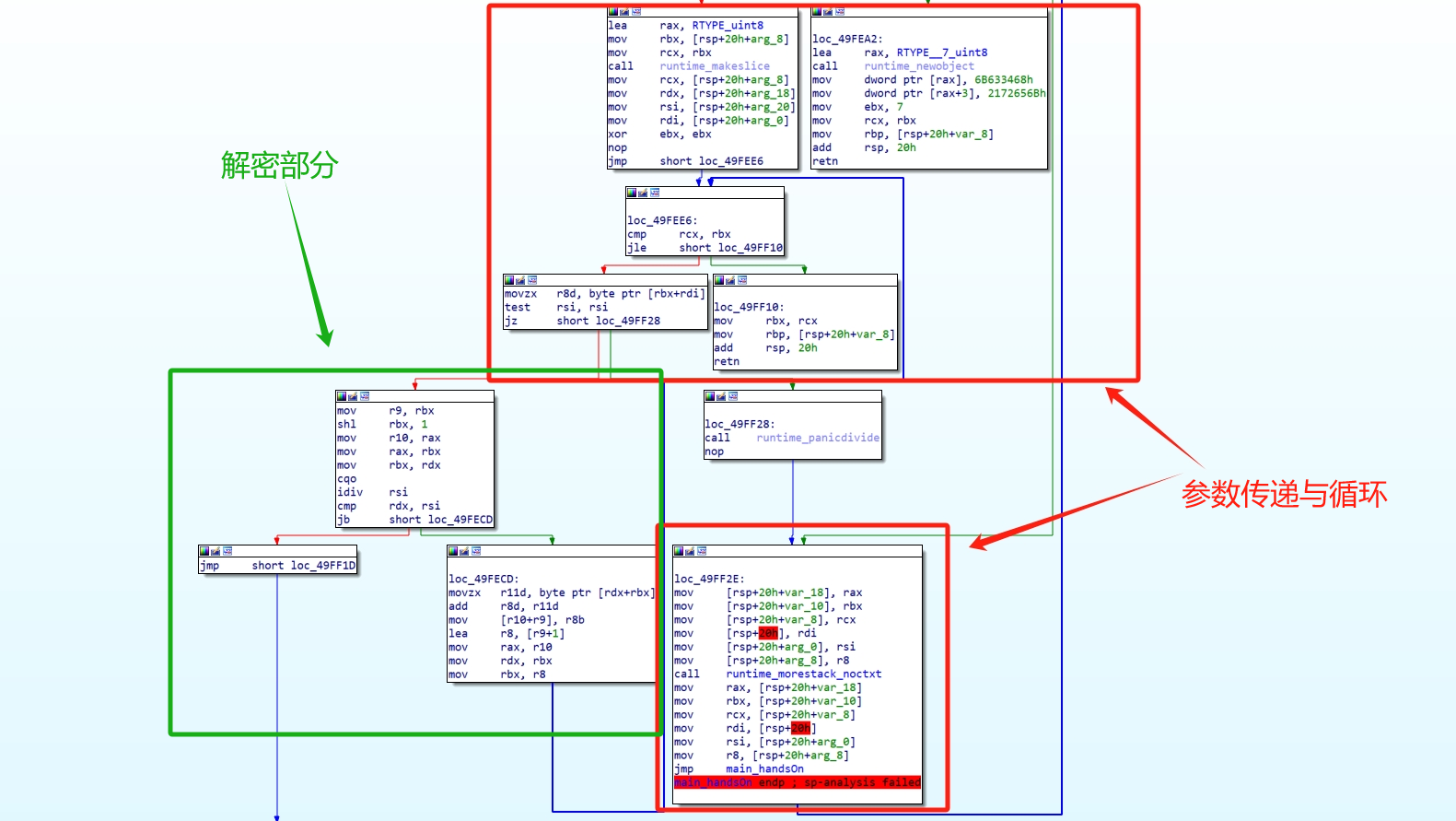
解密算法注意两条:
shl rbx, 1相当于乘2
idiv rsi; cmp rdx, rsi相当于将余数与除数比较。
idiv指令用rdx:rax的值除以rsi,将商保留在rax中,余数在rdx
再注意这三条:
lea r8, [r9+1]将r8+1
mov rbx, r8把r8给rbx
mov r9, rbx把rbx给r9
相当于进行一个计数器的迭代。好好好,妥妥的循环,接下来就是从内存地址里dump出数据,写解密脚本:
1 2 3 4 5 6 7 8 9 10 11 12 l1 = [0xfa , 0x3d , 0xaa , 0xf , 0xdc , 0x34 , 0x3a , 2 , 0x48 , 0xc9 , 0x2b , 0xec , 0x1e , 0x2d , 0xc7 , 0x67 , 0xb4 , 0x40 , 0xda , 0x67 , 0x1e , 0x14 , 0x5b , 0x86 , 0x3f , 0xe7 , 0x43 , 0x31 , 0x13 , 0x26 , 0xc1 , 0x12 , 0xe7 , 0x1f , 0x33 , 0xff , 0x6a , 0x85 , 0x41 , 0xd4 , 0x52 , 0x1e , 0x2 , 0x26 , 0xb4 , 0x42 , 0xbb , 0x60 , 0x18 , 0xff , 0x26 , 0xc2 , 0x2e , 0xbc , 0x60 , 0xf3 , 0xd5 , 0x28 , 0x86 , 0x3a , 0xef , 0x6b ] l2 = [0x60 , 0x78 , 0xd , 0x12 , 0xab , 0x41 , 0x34 ] print (hex (len (l1)))str = "" ans = [0 for i in range (0x3e )] for i in range (0x3e ): ans[i] =( l2[i * 2 % 7 ] + l1[i] ) % 256 str += chr (ans[i]) print (str )
得到flag
3 if-else
给了个if-else文件,很明显是ELF,试运行一下。
直接输flag。丢进IDA看一下:
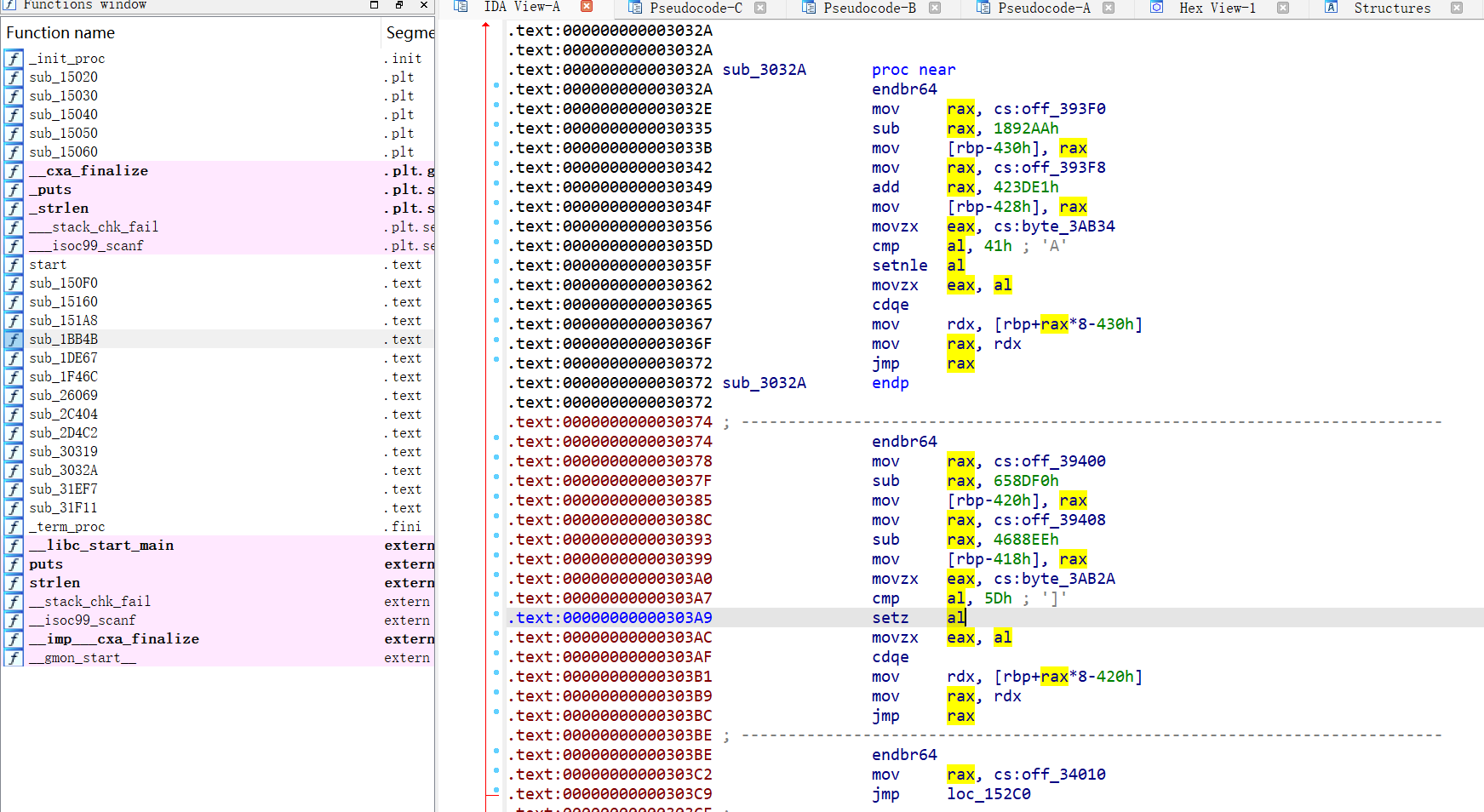
这是啥啊这是......红色的地方都是没有标号的函数,除了最上面一段已知标号可以F5的代码段外,还有无穷无尽的汇编代码...
但好像每段汇编代码都是相同的,抽一段分析一下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 .text:0000000000031C01 endbr64 .text:0000000000031C05 mov rax, cs:off_398D8 ; addr1 .text:0000000000031C0C add rax, 1CD0D0h .text:0000000000031C12 mov [rbp-30h], rax ; 参数1 .text:0000000000031C16 mov rax, cs:off_398E0 ; addr2 .text:0000000000031C1D add rax, 5B66F2h .text:0000000000031C23 mov [rbp-28h], rax ; 参数2 .text:0000000000031C27 movzx eax, cs:byte_3AB33 ; 载入目标字符 .text:0000000000031C2E cmp al, 3Ch ; '<' ; 与目标字符进行比较判断 .text:0000000000031C30 setnz al .text:0000000000031C33 movzx eax, al .text:0000000000031C36 cdqe .text:0000000000031C38 mov rdx, [rbp+rax*8-30h] ; 进行跳转地址的计算 .text:0000000000031C3D mov rax, rdx .text:0000000000031C40 jmp rax ; 跳转到对应地址处
看起来就是一个if-else的判断语句,经过计算,addr1和addr2其中必有一个等于fail函数的地址。
fail函数就是输出那个"wrong...."字符串的函数,很明显我们不能让程序跳转到它。
而上述这段代码引用的数据...还要拉好远去一堆乱码七糟的地方才能找出来。
如果数量有限的话,我们可以一个个地跟,一个个地判断,但是现在数量太多了,根本跟不完。
那么好,正片开始:
Angr是一个二进制分析框架和符号执行引擎,旨在帮助进行软件的逆向工程和漏洞发现。它提供了一个强大的平台,可以通过符号执行来分析和理解二进制程序。
我们可以利用angr来实现自动化程序分析,同时它还要配合claripy库进行字符的约束。
很遗憾第一次接触angr,比赛期间没能写出来py脚本,后来参考了一下学长的,自己改了一下。
脚本如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 import angrimport claripypro = angr.Project("./if-else" ) flag_chars = [claripy.BVS("flag_%d" % i, 8 ) for i in range (29 )] flag = claripy.Concat(*flag_chars + [claripy.BVV(b"\n" )]) initial_state = pro.factory.entry_state(stdin=flag) for i in flag_chars: initial_state.solver.add(i >= 0x20 ) initial_state.solver.add(i <= 0x7e ) initial_state.solver.add(flag_chars[0 ] == "Z" ) initial_state.solver.add(flag_chars[1 ] == "J" ) initial_state.solver.add(flag_chars[2 ] == "U" ) initial_state.solver.add(flag_chars[3 ] == "C" ) initial_state.solver.add(flag_chars[4 ] == "T" ) initial_state.solver.add(flag_chars[5 ] == "F" ) initial_state.solver.add(flag_chars[6 ] == "{" ) initial_state.solver.add(flag_chars[28 ] == "}" ) simu = pro.factory.simgr(initial_state) good_addr = 0x585213 def success (state ): output = state.posix.dumps(1 ) return b"Right!" in output def abort (state ): output = state.posix.dumps(1 ) return b"Wrong!" in output simu.explore(find= 0x431EF7 , avoid= 0x431F11 ) if simu.found: res = simu.found[0 ] flag = b"" for flag_char in flag_chars: flag += res.solver.eval (flag_char, cast_to=bytes ) print (flag) else : print ("No" )
运行结果:
4 verifier
好难的算法逆向.....扔进IDA:
C++的逆向,同时规定了文件以命令行传参的方式运行。
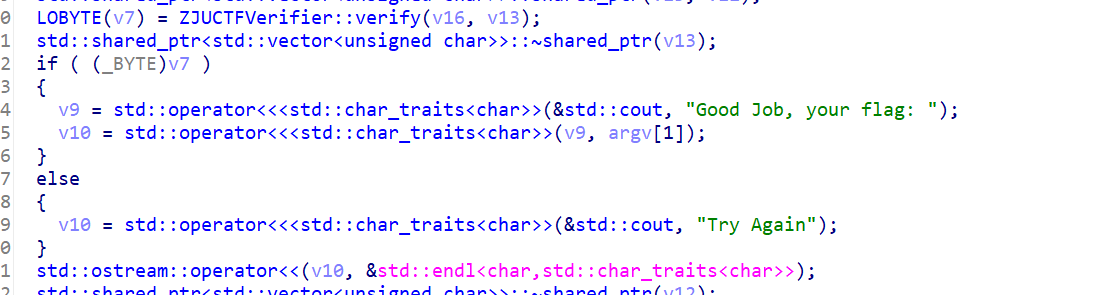
但还好,在main函数里面就一目了然,如果v7是1,那么表示我们可以得到flag。注意下面把argv[1]又输出出来....那不就是我们传进去的字符串....
然后就慢慢往上逆就好了,可以通过函数名称知道,main函数中主要有两个加密算法:
先看上面的算法ZJUCTFVerifier
函数有两个参数,分析可知,上面这段代码的意思就是把内存中一个标号为standard的32个byte数据截给v16和v15,并把两者同时作为参数传给ZJUCTFVerifier
在分析具体算法之前,我们可以先看看函数运行前后v16和v15的栈空间地址发生了什么变化。用gdb调试,在ZJUVerifier处打断点。
断前,观察栈空间数据,发现就是standard字符串的小端内容。
由于GDB会把栈空间所储存的内容当做一个long long类型的数据处理,所以在这里看到的起始是前八个字节的小端序。
断后,再次查看:
现在就很显然了,这个函数的功能就是实现了字符串中相邻两个字符的位置调换。好好好,这个算法就逆完了。
接下来看下面的加密函数verify
正片开始 :
其实根据上面的算法我们已经可知需要输入的字符串的长度为32了。
很明显,第二个32次迭代循环做的是加密后的明文和密文的一致性检测 ,所以本题是针对明文的加密,使其等于密文。
那么我们只需要关注第一个循环即可。
可以看到,第一个循环有一个内部的函数sub_9600,这个我们待会再看,先摸清楚这个算法的整体逻辑:
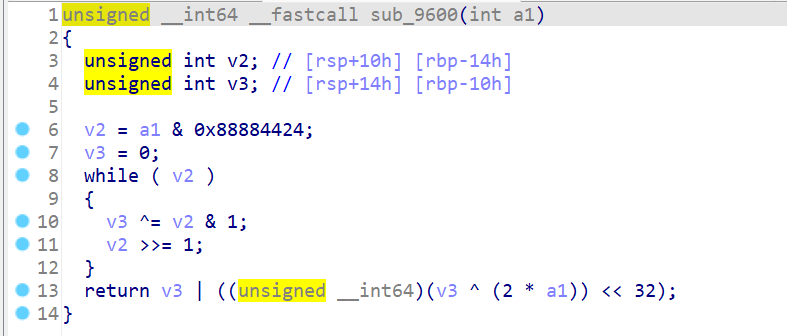
进入sub9600:
先将传入的数据与一个奇怪的数字进行异或,然后对其进行一系列的操作,最后返回一个莫名其妙的数。
注意: 该函数返回的是一个64位的无符号数。经过分析可知,该函数的作用为:
将传入的数字与0x88884424取与
将取与后的结果转化为二进制,统计位数为1的个数
如果统计结果是奇数,v3为1,否则为0
将传入的数字左移1位并将v3 与 其最低位进行异或。由于a1左移一位,最低位必然是0,所以相当于输出0则补1,输出1则补0。
最后将该数字作为返回值的高32位,将v3作为低32位,返回给原加密函数。
就上述思路,一口气把原函数吃下来:
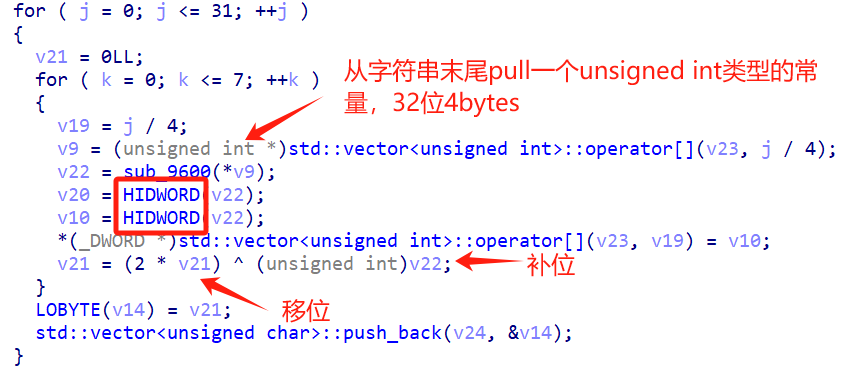
逐条分析:
v19 = j/4将原始的长度为32的明文以4个为一组,保证所取出的每个数据都是32位4bytes。
v9 = ....取出v23[j/4]下标的数据,连续取4个bytes,由小端规则转化为32位unsigned整形数。
v20和v10都表示sub_9600返回值的高32位数据,即进行移位补位之后的*v9
将第一次加密之后的结果放回去,迭代加密8次
有一个小坑,刚才说到sub_9600返回的是一个64位的unsigned long long,但在最后的v21=(2*v21)^(unsigend int)v22中却使用了unsigned int,将v22强制转化为32位。此时一定是保留v22的低32位而不是高32位。
下面还有两句:
这两句话的意思就是取迭代加密结果的低8位,也就是一个byte,push给result数组。
可以发现,LOBYTE在外层大循环中,执行32次。
32个明文字符,共分为8组,每组4个进行加密。组与组之间加密相互独立。
那也就是说,在每次加密的时候,当前密文值决定了生成的最低位的补位值(<<1)
好,逆着说这句话——在每次解密的时候,当前密文值决定了生成的最高位的补位值(>>1)
好好好,下面根据这句话来写解密算法:(整体逻辑如上,细节不表)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 standard = [0xa6 , 0xab , 0x38 , 0xe0 , 0xe7 , 0xb8 , 0xf2 , 0x86 , 0xc9 , 0xbb , 0xd8 , 0x6c , 0x3e , 0x8f , 0x6e , 0x6 , 0xc8 , 0xa2 , 0xdc , 0x15 , 0x91 , 0x8e , 0x51 , 0xff , 0xba , 0x9b ,0x73 , 0x70 , 0xa2 , 0x45 , 0x93 , 0xe9 ] standard_h = [0 for i in range (32 )] cipher_list = [0 for i in range (8 )] flag = '' stange_num = 0x88884424 def simulator_of_1 (num ): if num != 0 : if num % 2 == 1 : return 1 + simulator_of_1(num >> 1 ) else : return simulator_of_1(num >> 1 ) else : return 0 def decrypt (cipher ): text_low_bit = 0 text = 0 text = cipher for i in range (32 ): low_bit = cipher % 2 cipher >>= 1 text_low_bit = low_bit ^ (simulator_of_1(cipher & stange_num) % 2 ) text += text_low_bit << i cipher += text_low_bit << 31 return cipher def string_change (text ): string = '' for i in range (4 ): cha = text % 0x100 text >>= 8 string += chr (cha) n = '' for i in string: n = i + n return n for i in range (8 ): for j in range (2 ): standard_h[4 * i + j] = standard[4 * i + j + 2 ] standard_h[4 * i + j + 2 ] = standard[4 * i + j] for k in range (4 ): cipher_list[i] += standard_h[4 * i + k] << (k * 8 ) for i in range (8 ): flag += string_change(decrypt(cipher_list[i])) print ("ZJUCTF{" + flag + "}" )
运行结果: