引言:
在lab1的流水线CPU中,我们通过stall去解决指令与指令之间存在的数据冲突,但如果指令中存在的冲突过多,就会因为大量的stall而使CPU的CPI降低。且在本实验中,要将Core和RAM模块用总线加以连接,为满足Axi_liteCore在等待RAM的返回值时对Core中冲突控制的接管,我们需要将数据冲突用另一种方式去解决。
1 实验目的:

2 实验原理:
2-1 forwarding机制
在lab1的流水线CPU中,我们通过stall去解决指令与指令之间存在的数据冲突,但如果指令中存在的冲突过多,就会因为大量的stall而使CPU的CPI降低。且在本实验中,要将Core和RAM模块用总线加以连接,为满足Axi_liteCore在等待RAM的返回值时对Core中冲突控制的接管,我们需要将数据冲突用另一种方式去解决。
graph TD;
RaceControl -.处理.-> Core2MEM_FSM的回应
Core2MEM_FSM的回应 -.MEM_stall,IF_stall.-> RaceControl;
Forwarding_unit -.处理.-> Data_hazard;
众所周知,控制冲突时不需要stall的,所以我们实现forwarding的目的有两个(我个人的理解):
- 提高流水线CPU的运行效率,减少stall。
- 利用forwarding_unit解决数据冲突,将stall机制释放出来用于处理Core2MEM_FSM的回应。
2-2 AX14-lite总线内存模型
在我们原本的Pipeline中,分为Core和RAM两个模块且RAM有两个接口,且Core和RAM中的数据传输间隔一个时钟周期(Bram):
graph LR;
Pipeline --> Core;
Pipeline --> RAM;
RAM --> ro_addr;
ro_addr --> ro_rdata;
RAM --> rw_addr;
rw_addr --> rw_wdata;
但在我们的AX14-lite总线内存模型时,RAM只有一个接口,且Core与RAM的数据传输通过axi-lite协议,数据传输间隔不止一个时钟周期:
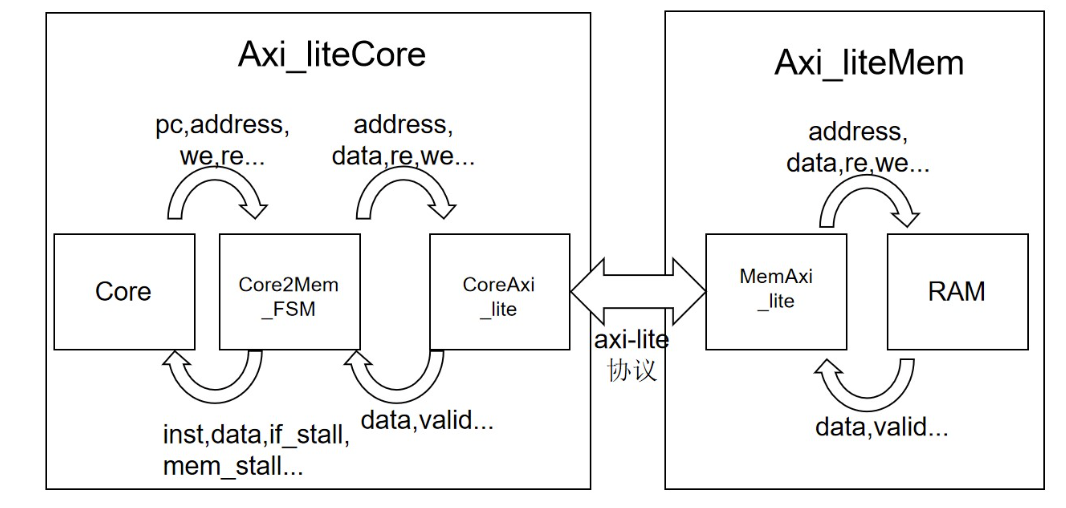
所以,在Core2MEM_FSM对Axi_liteMem发送请求时:
- 既要避免IF阶段和MEM阶段同时使用RAM而产生结构冲突(仲裁)
- 也要避免在Core等待RAM返回结果时由于stall的时钟周期数不足而导致数据没有及时返回。
3 实验步骤:
3-1 Forwarding机制的实现
Forwarding的基本原理就是在两指令产生数据冲突时,前一条指令的数据还未写回到寄存器之前,提前将该数据返回给后一条指令进行计算,从而避免数据冲突。通常情况下,forwarding机制触发时,前一条指令在MEM/WB阶段,后一条指令的EXE阶段,数据由MEM/WB阶段的rd传输给EXE阶段的rs1/rs2。
其中MEM/WB的rd又分为两种情况:
由R/I型指令直接在EXE阶段计算出的ALU_result
由L型指令通过访存读取出来的rw_rdata
在MEM阶段读出的rw_rdata会在下一时钟周期传输到WB阶段,实际上WB阶段不会进行访存,但该数据的来源仍然是RAM并非ALU,在本人的Pipeline中需要在WB阶段将这两种数据来源分开考虑,在本实验报告中将WB阶段来自MEM阶段的rw_rdata成为WB阶段的rw_rdata。
graph LR;
O((Data_Select)) --> rs1;
rs1 --> EXE;
O --> rs2;
rs2 --> EXE;
MEM --> ALU_result_MEM;
ALU_result_MEM --> O;
MEM --> rw_rdata_MEM;
rw_rdata_MEM --> O;
WB --> P(ALU_result_WB);
P(ALU_result_WB) --> O;
WB --> rw_rdata_WB;
rw_rdata_WB --> O;
3-1-1 ID与EXE两模块的调整
向zjgg的实验指导屈服了,在lab1里面本人将选择寄存器or立即数的MUX放在了ID阶段,抱歉在forwarding里面要把他搞回EXE.......
在forwarding当中,MEM和WB阶段向EXE阶段前递数据时,该数据可能并不会作为ALU的操作数.....比如
1
2
| add t2, t2, 2
bne zero, t2, pc + 2358
|
此时发现数据冲突(t2),由MEM阶段前递t2的数据给EXE进行判断,但这个时候EXE里ALU的操作数并不是zero和t2,而是pc和2358.....
在EXE中,跳转指令条件的判断是通过rs1和rs2的比较,但ALU的操作数却是经过MUX选择的.....
原本我们的ID只会给EXE阶段放出来MUX_result和rs1,rs2跳转判断的结果,但ID的rs1和rs2并未接收MEM/WB阶段的数据前递,导致跳转判断出错。看来在forwarding当中,lab1的数据处理结构并不能很好地处理B型指令。
为了forwarding大业!还是乖乖把MUX放到EXE吧.....
把ID阶段Decoder之外的所有模块放到EXE,包括读取寄存器,分支指令的初判断,Mux选择等。
更改之后的EXE阶段代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
| module EXE(
input [31:0]inst,
input [31:0]pc,
input [21:0]b,
input [63:0]rs1,
input [63:0]rs2,
input valid_EXE,
input [4:0]rs1_name,
input [4:0]rs2_name,
output rd_reg_write_EXE,
output [63:0]ALU_result,
output [63:0]pc_next,
output [4:0]rd_EXE,
output [63:0]addr_out,
output [7:0]mask_offset,
output rw_wmode,
output [63:0]rw_wdata,
output br_taken
);
ALU alu(
.a(Mux2_32_result_a),
.b(Mux2_32_result_b),
.alu_op(b[15:12]),
.res_p(ALU_result)
);
assign rd_reg_write_EXE = b[21];
wire pc_src;
assign pc_src = b[19];
wire [2:0]bralu_op;
assign bralu_op = b[11:9];
wire [63:0]pc_wire;
assign pc_wire = pc;
assign rd_EXE = inst[11:7];
wire less_for;
wire [63:0]alu_option_for;
Bomb bomb(
.I0(rs1),
.I1(rs2),
.less(less_for),
.alu_option(alu_option_for)
);
wire [31:0]imm;
wire [63:0]Mux2_32_result ;
wire [63:0]Mux2_32_result_b ;
wire [63:0]Mux2_32_result_a;
wire [1:0]alu_src_a ;
assign alu_src_a = b[8:7];
wire [1:0]alu_src_b;
assign alu_src_b = b[6:5];
wire [2:0]bralu_op;
assign bralu_op = b[11:9];
wire [2:0]immgen_op ;
assign immgen_op = b[18:16];
ImmGen gen(
.inst(inst),
.immgen_op(immgen_op),
.imm(imm)
);
Mux2_32 mux2(
.I0(rs2),
.I1({{32{imm[31]}},imm}),
.K(alu_src_b),
.result(Mux2_32_result_b)
);
Mux2_32 mux4(
.I0(rs1),
.I1(pc),
.K(alu_src_a),
.result(Mux2_32_result_a)
);
Mux4_32_pc mux3(
.I0(pc_wire + 4),
.I1(ALU_result),
.K(pc_src),
.branch_and(bralu_op),
.alu_option(alu_option_for),
.less(less_for),
.result(pc_next),
.br_taken(br_taken)
);
assign addr_out = ALU_result;
assign rw_wmode = b[20];
reg [7:0]mask;
wire [2:0]width = b[2:0];
always @(*) begin
case(width)
3'b000 :begin mask = 8'b00000000;end
3'b001 : begin mask = 8'b11111111;end
3'b010 : begin mask = 8'b00001111;end
3'b011 :begin mask = 8'b00000011;end
3'b100 :begin mask = 8'b00000001;end
3'b101 :begin mask = 8'b00001111;end
3'b110 :begin mask = 8'b00000011;end
3'b111 :begin mask = 8'b00000001; end
default : begin
mask = 8'b11111111;
end
endcase
end
assign rw_wdata = rs2 << ({3'b0,addr_out[2:0]}<<3);
assign mask_offset[7:0] = mask[7:0] << ({1'b0,addr_out[2:0]});
endmodule
|
3-1-2 Forwarding_unit
为了将RaceControl释放出来,我们需要用一个Forwarding判断模块去指导MEM/WB向EXE的数据前递。根据课件中的指导方案,实现该模块。

在EXE的rs1,rs2的传输接口中,再通过ForwardA,ForwardB选择数据传输。
该模块具体实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| module Forwarding(
input [4:0]rs1_EXE,
input [4:0]rs2_EXE,
input [4:0]rd_MEM,
input [4:0]rd_WB,
input [2:0]immgen_op,
input reg_write,
input reg_write_MEM,
input mem_load,
output reg [1:0]forward_A,
output reg [1:0]forward_B
);
always @(*) begin
if(rs1_EXE == rd_MEM && (mem_load | reg_write_MEM) && rs1_EXE != 0) begin
forward_A = 2'b10;
end else if(rs1_EXE == rd_WB && reg_write && rs1_EXE != 0 ) begin
forward_A = 2'b01;
end else begin
forward_A = 0;
end
if(rs2_EXE == rd_MEM && (mem_load | reg_write_MEM) && rs2_EXE != 0 && immgen_op != 3'b001) begin
forward_B = 2'b10;
end else if(rs2_EXE == rd_WB && reg_write && rs2_EXE != 0 && immgen_op != 3'b001) begin
forward_B = 2'b01;
end else begin
forward_B = 0;
end
end
endmodule
|
可以看到我们的判断并不只是简单的对比rs1与rd的名称是否相同,还加了一些判断条件:
- Forwarding只发生在MEM/WB指令对rd寄存器写寄存器时触发
在某些情况下,前一条指令并不对rd寄存器进行写操作,或者根本没有rd寄存器比如:
1
2
3
| bne ra, t2, pc + 1111
add ......
sub ......
|
在该指令中只有rs1,rs2,并没有rd,如果该分支指令不生效,那么就要确保其在MEM/WB阶段时,不因rd(虽然没有,但我们对rd寄存器号的提取方法是直接截取inst。可以认为在此指令中rd是垃圾数据)与EXE的rs1/rs2恰巧相同而触发forwarding。
所以我们需要保证forwarding触发时,MEM/WB的阶段inst确实在写rd。
有如下代码段:
当add指令运行到MEM阶段时,li指令在EXE阶段,此时rs2_EXE == 3, rd_MEM == 3, rd_MEM == rs2_EXE
在这里,rs2_EXE无疑是垃圾数据,但由于我们对rs2寄存器号的提取方法是直接截取inst,所以在这里rs2也是有数值的(imm小于5位时等于imm),且恰巧和add指令的rd寄存器号相等。显然在这种情况下,并不需要forwarding,所以需要辨别EXE当前指令的类型,这里我们使用immgen_op进行判断。
1
2
3
4
5
6
7
8
9
10
11
12
13
| always @(*) begin
case (immgen_op)
3'b000: imm_reg = 0;
3'b001: imm_reg = {{20{inst[31]}},inst[31:20]};
3'b010: imm_reg = {{20{inst[31]}},inst[31:25],inst[11:7]};
3'b011: imm_reg = {{20{inst[31]}},inst[7],inst[30:25],inst[11:8], 1'b0};
3'b100: imm_reg = {inst[31:12], 12'b0};
3'b101: imm_reg = {{11{inst[31]}}, inst[20], inst[19:12], inst[31], inst[30:21], 1'b0};
default:begin
imm_reg = 0;
end
endcase
end
|
需要明确,在此种情况下,imm只会在rs2_EXE的位置出现,所以我们只要保证在rs2_EXE的forwarding判断时EXE当前的指令不是I型即可
3-1-3 EXE接口的数据选择
这里不需要分析什么,按课件上的指导直接干:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| EXE EXE1(
.inst(inst_EXE),
.pc(pc_EXE),
.b(b_EXE),
.valid_EXE(valid_EXE),
.rs1((forward_A == 2'b00) ? rs1_data_EXE : ( (forward_A == 2'b10) ? ((b_MEM[4:3] == 2'b10) ?Processed_MEM :ALU_result_MEM ): ((b_WB[4:3] == 2'b10) ? Ram_to_Path : ALU_result_WB))),
.rs2((forward_B == 2'b00) ? rs2_data_EXE : ( (forward_B == 2'b10) ? ((b_MEM[4:3] == 2'b10) ?Processed_MEM :ALU_result_MEM ): ((b_WB[4:3] == 2'b10) ? Ram_to_Path : ALU_result_WB))),
.rs1_name(rs1_EXE),
.rs2_name(rs2_EXE),
.ALU_result(ALU_result_EXE),
.rd_reg_write_EXE(rd_reg_write_EXE),
.rd_EXE(rd_EXE),
.pc_next(pc_in),
.br_taken(npc_sel_EXE),
.addr_out(addr_out),
.mask_offset(mask_offset),
.rw_wdata(rw_wdata),
.rw_wmode(rw_wmode)
);
|
唯一需要注意的在MEM/WB前递数据时,还需要进行数据来源的选择~
b[4:3]是wb_sel,表示写回寄存器的数据是来自RAM还是ALU_result,在此我们利用它去区分数据来源。
Processed_MEM 是在MEM阶段从RAM中读出,并进行指定位宽截取,要在WB阶段写回Reg的数据。
Ram_to_Path是在WB阶段从RAM中读出,要写回Reg的数据。
3-1-4 RaceControl置空
我们实现了利用forwarding机制来解决数据冲突,就不再需要stall了。所以在RaceControl里面只保留flush信号,将所有stall信号置0
3--1-5 Forwarding仿真验证:
把文件拖进submit进行仿真验证:

Pass,看一下仿真波形和运行时间~

由于没有了stall,1358ps就跑完了全部指令。
\遥遥领先/ \遥遥领先/ \遥遥领先/
3-2 AxI4-lite总线模型
3-2-1 RaceControl接管
在Forwarding中,我们将RaceControl释放了出来,在AXI4-lite总线中,RaceControl的stall机制不再为数据冲突服务,而会被AXI_liteCore接管,解决在RAM尚未返回valid信号时,Core中指令的等待。
此时,AXI_liteCore会给Core传递两个信号:IF_Stall和MEM_stall,分别处理在IF,MEM两阶段向RAM发送请求时Core中指令的等待。
RaceControl的具体实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
| module RaceControl(
input IF_stall,
input MEM_stall,
input npc_sel_EXE,
input [4:0]rs1_ID,
input [4:0]rs2_ID,
input [4:0]rs1_EXE,
input [4:0]rs2_EXE,
input [4:0]rd_EXE,
input [4:0]rd_MEM,
input [4:0]rd_WB,
input rd_reg_write,
input re_MEM_MEM,
input we_MEM_EXE,
input reg_WB,
output pc_stall,
output IFID_stall,
output IFID_flush,
output IDEXE_flush,
output IDEXE_stall,
output EXEMEM_stall,
output EXEMEM_flush,
output MEMWB_stall,
output MEMWB_flush
);
wire data_race_if = ((rs1_EXE == rd_MEM)|(rs2_EXE == rd_MEM))&(re_MEM_MEM&~we_MEM_EXE);
wire predict_flush = npc_sel_EXE;
assign pc_stall = MEM_stall | IF_stall;
assign IFID_stall = MEM_stall | data_race_if;
assign IFID_flush = (predict_flush | IF_stall)&~IFID_stall;
assign IDEXE_stall = predict_flush & IF_stall | MEM_stall | data_race_if;
assign IDEXE_flush = ~IDEXE_stall & predict_flush;
assign EXEMEM_stall = MEM_stall;
assign EXEMEM_flush = ~EXEMEM_stall & (data_race_if | predict_flush & IF_stall);
assign MEMWB_stall = 1'b0;
assign MEMWB_flush = MEM_stall;
endmodule
|
需要注意的是:
- 在AXI4-lite中re_MEM_MEM信号和we_MEM_EXE理论上不会同时为1,且仅在re_MEM_MEM生效时触发stall信号;
- 在AXI4-lite中stall信号不会和flush信号同时触发, 也就是说,在等待RAM传回数据时,所有阶段都要等待,即便遇到了控制冲突需要flush,也要等stall信号结束后才可以flush。
3-2-2 Core2MEM_FSM模块实现:
Core2MEM_FSM模块需要完成Core和RAM之间的数据与信号传输,我们使用一个有限状态机来实现:
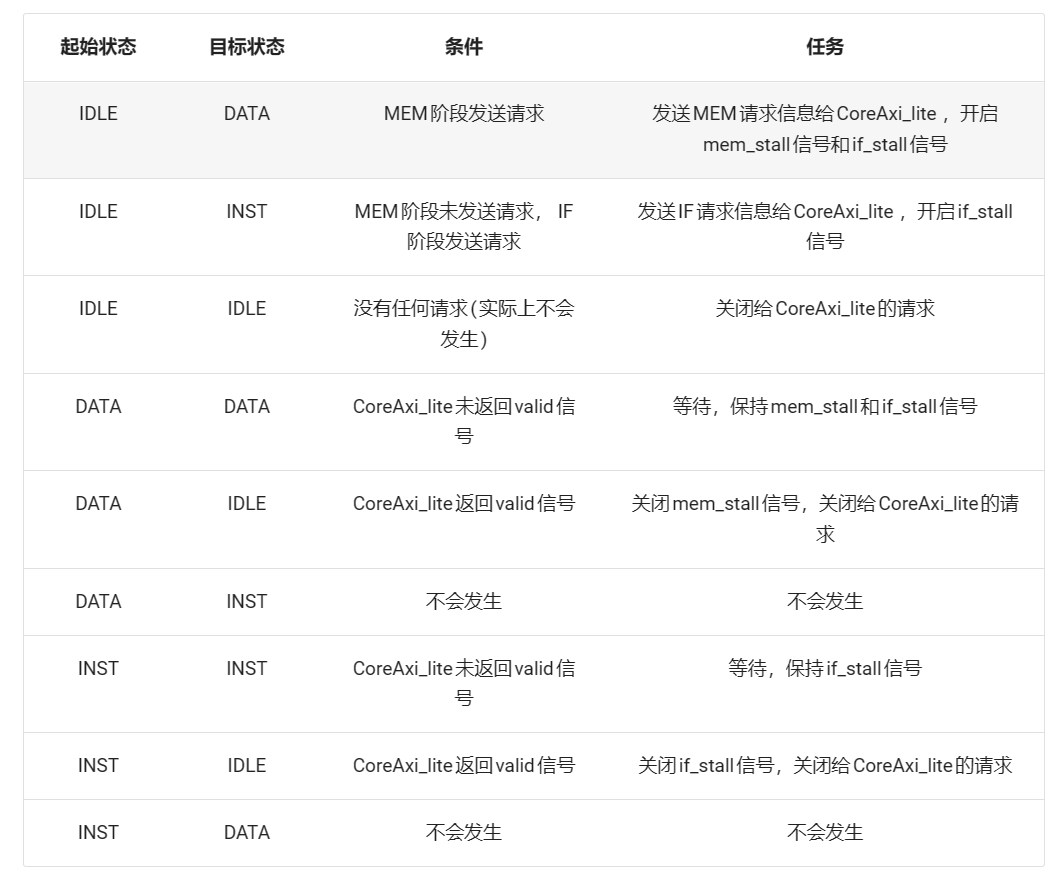
模块具体实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
| module Core2Mem_FSM (
input wire clk,
input wire rstn,
input wire [63:0] pc,
input wire if_request,
input wire [63:0] address_cpu,
input wire wen_cpu,
input wire ren_cpu,
input wire [63:0] wdata_cpu,
input wire [7:0] wmask_cpu,
output [31:0] inst,
output [63:0] rdata_cpu,
output if_stall,
output mem_stall,
output reg [63:0] address_mem,
output reg ren_mem,
output reg wen_mem,
output reg [7:0] wmask_mem,
output reg [63:0] wdata_mem,
input wire [63:0] rdata_mem,
input wire valid_mem
);
reg [1:0]state = 0;
reg mem_open = 0;
reg if_open = 0;
reg inst_open = 0;
reg rdata_open = 0;
reg ren_keep = 0;
reg wen_keep = 0;
reg [63:0]address_keep=0;
reg [7:0]wmask_keep=0;
reg [63:0]wdata_keep=0;
reg [63:0]inst_keep=0;
reg keep=0;
assign if_stall = (if_open == 1'b1);
assign mem_stall = (mem_open == 1'b1) ? 1 : 0;
assign inst = (inst_open ) ? (((pc-4 >> 2)%2 == 0 ) ? inst_keep[31:0] : inst_keep[63:32]) : 0;
assign rdata_cpu = (rdata_open ) ? rdata_mem : 0;
always @(posedge clk or negedge rstn) begin
if(!rstn) begin
keep <= 0;
if_open <= 0;
mem_open <= 0;
inst_open <= 0;
rdata_open <= 0;
address_mem <= 0;
ren_mem <= 0;
wen_mem <= 0;
wmask_mem <= 0;
wdata_mem <= 0;
end else begin
case (state)
2'b00: begin
if(keep)begin
ren_mem <= ren_keep;
wen_mem <= wen_keep;
address_mem <= address_keep;
wmask_mem <= wmask_keep;
wdata_mem <= wdata_keep;
mem_open <= 1;
if_open <= 1;
state <= 2'b01;
end else if(wen_cpu | ren_cpu) begin
ren_mem <= ren_cpu;
wen_mem <= wen_cpu;
address_mem <= address_cpu;
wmask_mem <= wmask_cpu;
wdata_mem <= wdata_cpu;
mem_open <= 1;
if_open <= 1;
state <= 2'b01;
end
else if(if_request)begin
state <= 2'b10;
if_open <= 1;
wmask_mem <= 8'b11111111;
mem_open <= 0;
address_mem <= pc;
ren_mem <= 1;
wen_mem <= 0;
end
end
2'b01: begin
if(valid_mem) begin
mem_open <= 0;
ren_mem <= 0;
state <= 2'b00;
rdata_open <= 1;
if_open <= 0;
if(keep) inst_open <= 1;
if(keep) address_mem <= pc ;
keep <= 0;
wen_mem <= 0;
end else if(!valid_mem) begin
mem_open <= mem_open;
end
end
2'b10: begin
if(valid_mem)begin
if_open <= 0;
if(~keep) mem_open <= 0;
inst_keep <= rdata_mem;
ren_mem <= 0;
wen_mem <= 0;
state <= 2'b00;
inst_open <= 1;
end else begin
address_mem <= pc;
if(if_request == 0 && (ren_cpu | wen_cpu)) begin
keep <= 1;
mem_open <= 1;
ren_keep <= ren_cpu;
wen_keep <= wen_cpu;
address_keep <= address_cpu;
wmask_keep <= wmask_cpu;
wdata_keep <= wdata_cpu;
end
end
end
2'b11: begin
end
endcase
end
end
endmodule
|
解释一下在上述代码中比较重要的几点:
- 在FSM中模拟RAM接口的pc前递与inst截取:
assign inst = (inst_open ) ? (((pc-4 >> 2)%2 == 0 ) ? inst_keep[31:0] : inst_keep[63:32]) : 0;
可以看到在上述代码中如上赋值语句。在我们原来的Core模块中,当Pipeline在执行当前inst指令的同时,要向RAM发送下一条inst的请求,也就是当pc = pc_IF时,向RAM中传入的pc是pc_IF + 4 。
在Core与Core2MEM_FSM的接口中,我们传入的是pc_IF + 4,所以对于截取指令而言,应用pc_IF截取,取指令时,要用pc_IF + 4访存。
1
2
3
4
5
6
7
8
| reg ren_keep = 0;
reg wen_keep = 0;
reg [63:0]address_keep=0;
reg [7:0]wmask_keep=0;
reg [63:0]wdata_keep=0;
reg [63:0]inst_keep=0;
reg keep=0;
|
在上述代码中,我们引入了一套keep数据,用于保存在向RAM发送指令读取请求的过程中传入的访存信息。
因在FSM向RAM传输信号的多时钟周期内,上一条指令在Core中运行。当处理sd,ld等写存/访存信号时,Core向FSM传输相应的数据与信号,但此时FSM并未完成当前的取指令任务。
所以在这种情况下,我们需要做两件事情:
- 触发MEM_stall信号,将Core中所有任务停住
- 保存Core向FSM传输的数据与信号,在FSM结束取指令的任务时,立刻将状态改为DATA,并利用keep的数据进行写存/访存。
具体实现的代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| 2'b00: begin
if(keep)begin
ren_mem <= ren_keep;
wen_mem <= wen_keep;
address_mem <= address_keep;
wmask_mem <= wmask_keep;
wdata_mem <= wdata_keep;
mem_open <= 1;
if_open <= 1;
state <= 2'b01;
..............
..............
if(if_request == 0 && (ren_cpu | wen_cpu)) begin
keep <= 1;
mem_open <= 1;
ren_keep <= ren_cpu;
wen_keep <= wen_cpu;
address_keep <= address_cpu;
wmask_keep <= wmask_cpu;
wdata_keep <= wdata_cpu;
end
|
这样,就利用FSM实现了两信号的仲裁。
3-2-3 AXI4-lite总线测试
仿真测试:
pass~
上板验证:

pass~
4 Questions
1.在引入 Forwarding 机制后,是否意味着 stall 机制就不再需要了?为什么?
? 拿到这个题我是懵的。。因为在我的forwarding里面完全没有stall......后来看了一下自己的波形,原来自己的代码中把load_use的冲突通过在EXE阶段前递address的方法给解决了......这样就不用stall了..... ? 控制冲突? 我好像也把控制冲突的stall优化掉了,只调用了flush......可能我写的不规范.... 那就当作我是按照一般思路来写的叭......
不是,因为 Forwarding 机制只能解决部分数据冲突,例如 load-use 冲突就无法通过 Forwarding 完全解决,由于我们使用的是Bram,load指令需要先 stall 一个周期后再使用 Forwarding。
其次,控制冲突也需要通过 stall 才能解决。
2.你认为 Forwarding 机制在实际的电路设计中是否存在一定的弊端?和单纯的 stall 相比它有什么缺点?
电路复杂性增加:引入Forwarding 机制会增加处理器的复杂性。需要在电路中添加额外的逻辑来检测和转发数据,这会增加电路的面积和功耗。此外,需要确保数据正确地转发到目标指令,这可能需要更多的管脚和布线,增加了设计和验证的复杂性。
电路延迟增加:尽管Forwarding 机制可以减少数据冲突带来的停顿,但它也会引入一定的延迟。数据的转发需要经过一些逻辑电路和电缆,这会导致一定的传输延迟。在某些情况下,这种延迟可能会超过等待停顿的时间,从而导致性能下降。
电路容错性降低:Forwarding 机制需要准确地检测和转发数据,如果出现错误或故障,可能会导致数据错误地转发或未能正确转发。这可能会导致指令执行错误,影响程序的正确性和稳定性。相比之下,使用插入空闲周期(stall)的方法更加简单,且相对容易实现和验证。
限制了某些特定的冲突:Forwarding 机制主要用于解决数据冲突,而对于其他类型的冲突,如控制冲突,Forwarding 机制并不适用。在这些情况下,仍然需要使用插入空闲周期的方法来解决。
综上所述,Forwarding 机制在某些特定冲突场景下的适用性有限。
3.不考虑 AXI4-lite 总线的影响,引入 Forwarding 机制之后 cpi 和 stall 相比提升了那些?
引入Forwarding机制后,以下方面会有提升:
- CPI(Cycles Per Instruction):通过减少或消除执行阶段的停顿,每条指令平均所需的周期数会降低,因此CPI会减少,即执行每条指令所需的平均周期数会下降。
- 吞吐量提升:数据前递减少了流水线的停顿,从而提高了流水线的吞吐量,允许更多的指令并行地在不同的流水线阶段执行。
- 处理器效率提升:处理器效率提高,因为处理器能更紧凑地执行指令,减少浪费周期。
- 整体性能提高:整体性能提高,程序执行时间缩短。
4. 计算加入 AXI4-lite 总线之后的 cpi,思考 cpi 的值受到什么因素的制约,考虑可能的提升方法?
观察仿真波形,起始时间
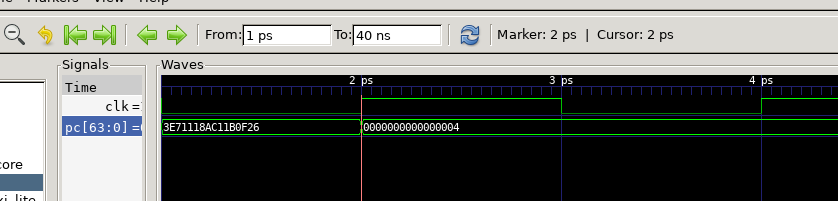
结束时间

总周期数
指令数
CPI为:
- 访存延迟:AXI4-lite 总线是一种存储器访问协议,用于处理器和外部存储器(如RAM)之间的数据传输。在使用该总线进行存储器访问时,会存在访存延迟。每次进行存储器读取或写入时,需要等待一定的时间才能获取或写入数据。可以看到每次我们从向RAM发送请求到RAM返回数据都要间隔10个时钟周期,这会增加指令的执行时间,从而提高 CPI。
- 数据冲突:在使用 AXI4-lite 总线时,可能会产生数据冲突。当多条指令需要同时访问同一个存储器位置时,会出现数据冲突,需要等待数据可用后再继续执行。这会导致停顿和延迟,增加 CPI。
- 控制冲突:类似于数据冲突,控制冲突也可能发生在使用 AXI4-lite 总线时。当分支指令或跳转指令需要根据存储器读取结果或其他外部事件来确定执行路径时,可能会出现控制冲突。这会导致停顿和延迟,增加 CPI。例如在IF指令还未取回时接受到了MEM的访存信号等。
- 提前预取数据:在发生存储器访问之前,可以通过提前预取(prefetching)数据来减少访存延迟。通过在存储器访问之前预先将数据加载到高速缓存中,可以避免等待数据的时间,从而降低 CPI。
- 使用高效的缓存和缓存替换策略:使用高速缓存可以减少对外部存储器的访问次数,从而降低访存延迟和数据冲突的影响。此外,选择合适的缓存替换策略(如最近最少使用算法)可以提高缓存的命中率,进一步降低 CPI。
- 软件优化:通过对代码进行优化,如减少存储器访问次数、减少数据依赖关系等,可以降低访存延迟和数据冲突的影响,从而降低 CPI。
- 采用多发射技术:Core中采用双发射技术运行,每次执行两条指令,减少等待的时间,加快运行速率,降低CPI。
5.尝试分析添加 Forwarding 后整体设计的关键路径。
将文件加入vivado工程并进行综合。
分析时间报告:

找到时间最长的路径:

(看不懂一点。。。。。)
看起来和lab1一样,是控制冲突处理的过程:
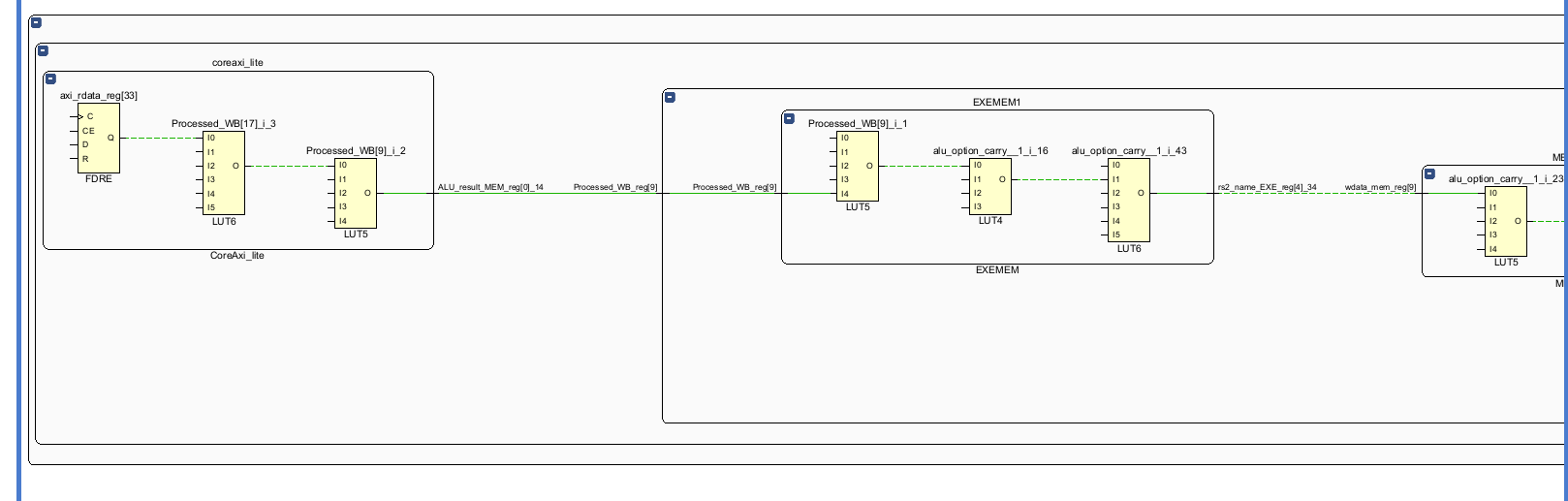
(前面为什么有Processed_WB。。。。。不管了)EXEMEM中将Processed_MEM传递给Processed_WB
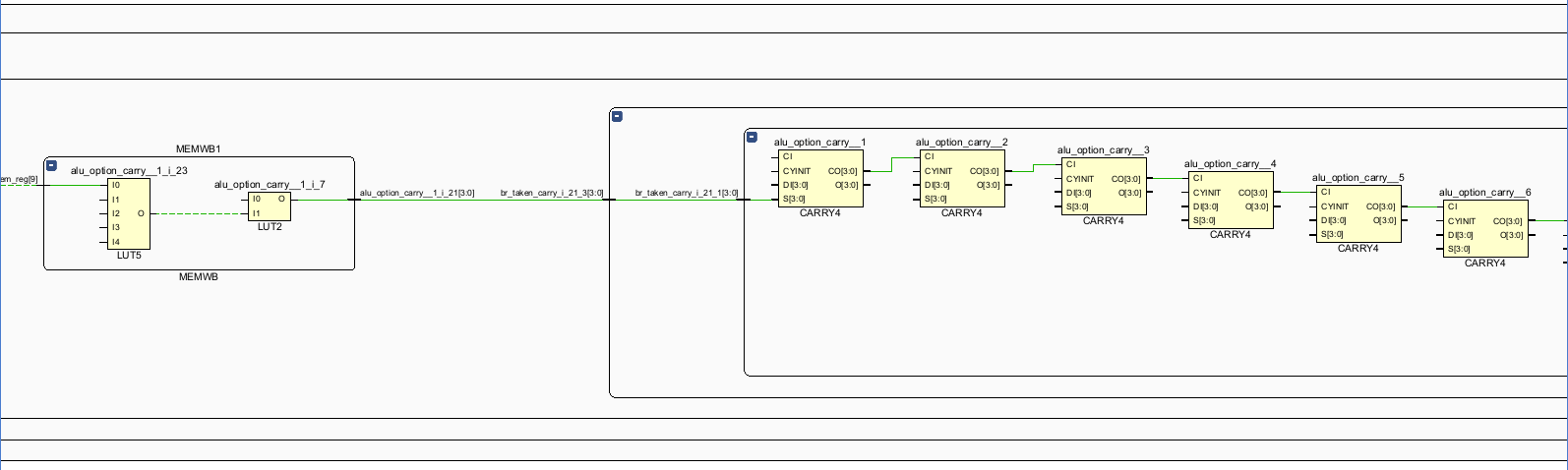
EXE中通过alu_option, less等跳转辅助判断信号,输出br_taken
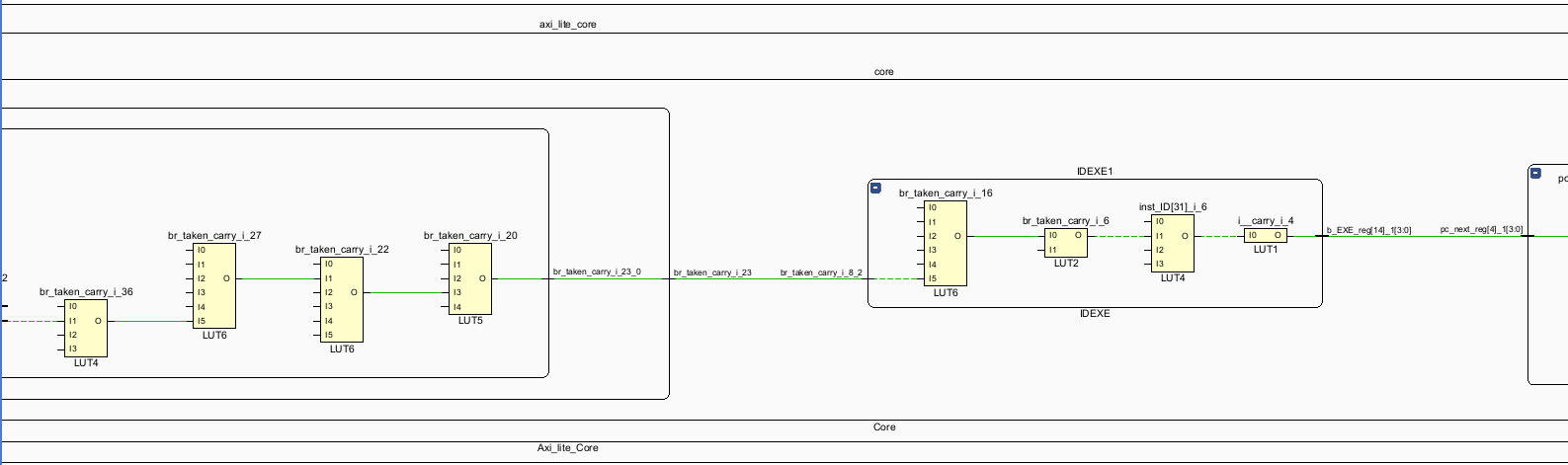
同时,br_taken通过旁路逐级返回到IF。
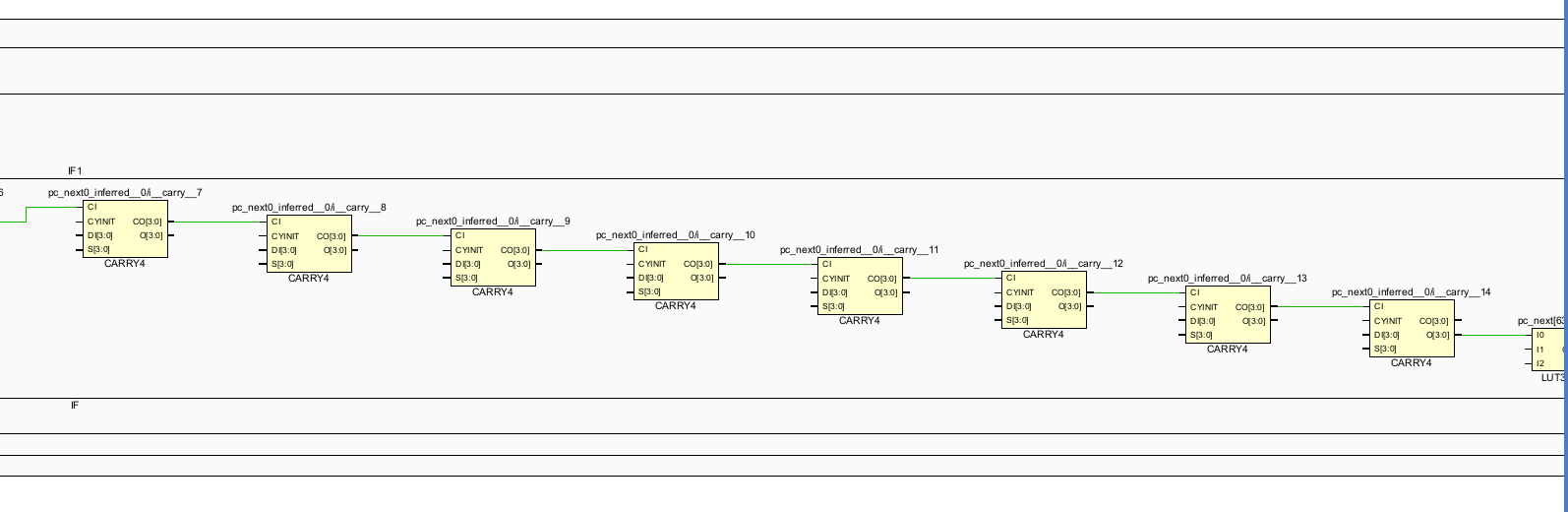
在br_taken的条件下,pc_next变为pc_in。
EXE阶段产判断跳转指令的跳转条件,并生成br_taken信号
br_taken信号传递给Race_Control模块,生成IFID_Flush的信号传递给IFID阶段间寄存器插入bubble。
br_taken信号传递给Race_Control模块,生成IDEXE_Flush的信号传递给IDEXE阶段间寄存器插入bubble
br_taken信号指挥调度IF阶段的pc为跳转之后的pc。